1. What is MLOps?
Machine Learning Project
2012년 Alexnet 이후 CV, NLP를 비롯하여 데이터가 존재하는 도메인이라면 어디서든 머신러닝과 딥러닝을 도입하고자 하였습니다.
딥러닝과 머신러닝은 AI라는 단어로 묶이며 불렸고 많은 매체에서 AI의 필요성을 외쳤습니다. 그리고 무수히 많은 기업에서 머신러닝과 딥러닝을 이용한 수많은 프로젝트를 진행하였습니다. 하지만 그 결과는 어떻게 되었을까요?
엘리먼트 AI의 음병찬 동북아 지역 총괄책임자는 "10개 기업에 AI 프로젝트를 시작한다면 그중 9개는 컨셉검증(POC)만 하다 끝난다"고 말했습니다.
이처럼 많은 프로젝트에서 머신러닝과 딥러닝은 이 문제를 풀 수 있을 것 같다는 가능성만을 보여주고 사라졌습니다. 그리고 이 시기쯤에 AI에 다시 겨울이 다가오고 있다는 전망도 나오기 시작했습니다.
왜 프로젝트 대부분이 컨셉검증(POC) 단계에서 끝났을까요?
머신러닝과 딥러닝 코드만으로는 실제 서비스를 운영할 수 없기 때문입니다.
실제 서비스 단계에서 머신러닝과 딥러닝의 코드가 차지하는 부분은 생각보다 크지 않기 때문에, 단순히 모델의 성능만이 아닌 다른 많은 부분을 고려해야 합니다.
구글은 이런 문제를 2015년 Hidden Technical Debt in Machine Learning Systems에서 지적한 바 있습니다.
하지만 이 논문이 나올 당시에는 아직 많은 머신러닝 엔지니어들이 딥러닝과 머신러닝의 가능성을 입증하기 바쁜 시기였기 때문에, 논문이 지적하는 바에 많은 주의를 기울이지는 않았습니다.
그리고 몇 년이 지난 후 머신러닝과 딥러닝은 가능성을 입증해내어, 이제 사람들은 실제 서비스에 적용하고자 했습니다.
하지만 곧 많은 사람이 실제 서비스는 쉽지 않다는 것을 깨달았습니다.
Devops
MLOps는 이전에 없던 새로운 개념이 아니라 DevOps라고 불리는 개발 방법론에서 파생된 단어입니다. 그렇기에 DevOps를 이해한다면 MLOps를 이해하는 데 도움이 됩니다.
DevOps
DevOps는 Development(개발)와 Operations(운영)의 합성어로 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말합니다. DevOps의 목적은 소프트웨어 개발 조직과 운영 조직간의 상호 의존적 대응이며 조직이 소프트웨어 제품과 서비스를 빠른 시간에 개발 및 배포하는 것을 목적으로 합니다.
Silo Effect
그럼 간단한 상황 설명을 통해 DevOps가 왜 필요한지 알아보도록 하겠습니다.
서비스 초기에는 지원하는 기능이 많지 않으며 팀 또는 회사의 규모가 작습니다. 이때에는 개발팀과 운영팀의 구분이 없거나 작은 규모의 팀으로 구분되어 있습니다. 핵심은 규모가 작다는 것에 있습니다. 이때는 서로 소통할 수 있는 접점이 많고, 집중해야 하는 서비스가 적기 때문에 빠르게 서비스를 개선해 나갈 수 있습니다.
하지만 서비스의 규모가 커질수록 개발팀과 운영팀은 분리되고 서로 소통할 수 있는 채널의 물리적인 한계가 오게 됩니다. 예를 들어서 다른 팀과 함께하는 미팅에 팀원 전체가 미팅을 하는 것이 아니라 각 팀의 팀장 혹은 소수의 시니어만 참석하여 미팅을 진행하게 됩니다. 이런 소통 채널의 한계는 필연적으로 소통의 부재로 이어지게 됩니다. 그러다 보면 개발팀은 새로운 기능들을 계속해서 개발하고 운영팀 입장에서는 개발팀에서 개발한 기능이 배포 시 장애를 일으키는 등 여러 문제가 생기게 됩니다.
위와 같은 상황이 반복되면 조직 이기주의라고 불리는 사일로 현상이 생길 수 있습니다.

사일로(silo)는 곡식이나 사료를 저장하는 굴뚝 모양의 창고를 의미한다. 사일로는 독립적으로 존재하며 저장되는 물품이 서로 섞이지 않도록 철저히 관리할 수 있도록 도와준다.
사일로 효과(Organizational Silos Effect)는 조직 부서 간에 서로 협력하지 않고 내부 이익만을 추구하는 현상을 의미한다. 조직 내에서 개별 부서끼리 서로 담을 쌓고 각자의 이익에만 몰두하는 부서 이기주의를 일컫는다.
사일로 현상은 서비스 품질의 저하로 이어지게 됩니다. 이러한 사일로 현상을 해결하기 위해 나온 것이 바로 DevOps입니다.
CI/CD
Continuous Integration(CI) 와 Continuous Delivery (CD)는 개발팀과 운영팀의 장벽을 해제하기 위한 구체적인 방법입니다.
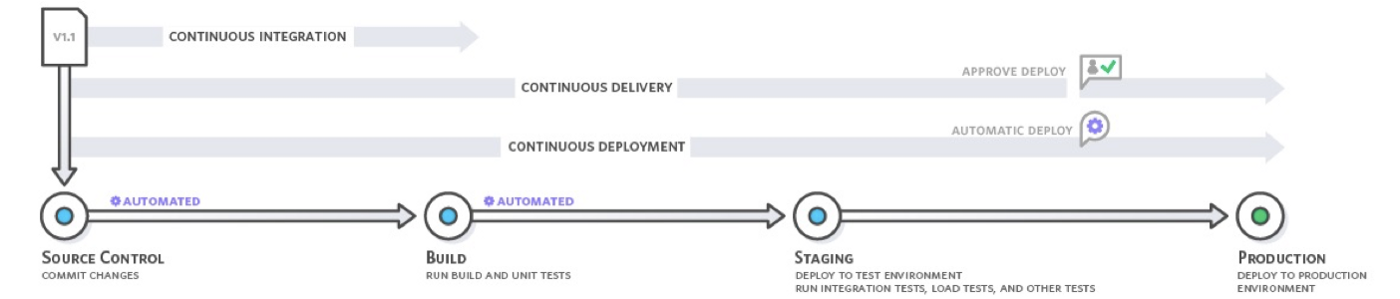
이 방법을 통해서 개발팀에서는 운영팀의 환경을 이해하고 개발팀에서 개발 중인 기능이 정상적으로 배포까지 이어질 수 있는지 확인합니다. 운영팀은 검증된 기능 또는 개선된 제품을 더 자주 배포해 고객의 제품 경험을 상승시킵니다.
앞에서 설명한 내용을 종합하자면 DevOps는 개발팀과 운영팀 간의 문제가 있었고 이를 해결하기 위한 방법론입니다.
MLOps
1) ML+Ops
MLOps는 Machine Learning 과 Operations의 합성어로 DevOps에서 Dev가 ML로 바뀌었습니다. 이제 앞에서 살펴본 DevOps를 통해 MLOps가 무엇인지 짐작해 볼 수 있습니다. “MLOps는 머신러닝팀과 운영팀의 문제를 해결하기 위한 방법입니다.” 이 말은 머신러닝팀과 운영팀 사이에 문제가 발생했다는 의미입니다. 그럼 왜 머신러닝팀과 운영팀에는 문제가 발생했을까요? 두 팀 간의 문제를 알아보기 위해서 추천시스템을 예시로 알아보겠습니다.
Rule Based
처음 추천시스템을 만드는 경우 간단한 규칙을 기반으로 아이템을 추천합니다. 예를 들어서 1주일간 판매량이 가장 많은 순서대로 보여주는 식의 방식을 이용합니다. 이 방식으로 모델을 정한다면 특별한 이유가 없는 이상 모델의 수정이 필요 없습니다.
Machine Learning
서비스의 규모가 조금 커지고 로그 데이터가 많이 쌓인다면 이를 이용해 아이템 기반 혹은 유저 기반의 머신러닝 모델을 생성합니다. 이때 모델은 정해진 주기에 따라 모델을 재학습 후 재배포합니다.
Deep Learning
개인화 추천에 대한 요구가 더 커지고 더 좋은 성능을 내는 모델을 필요해질 경우 딥러닝을 이용한 모델을 개발하기 시작합니다. 이때 만드는 모델은 머신러닝과 같이 정해진 주기에 따라 모델을 재학습 후 재배포합니다.
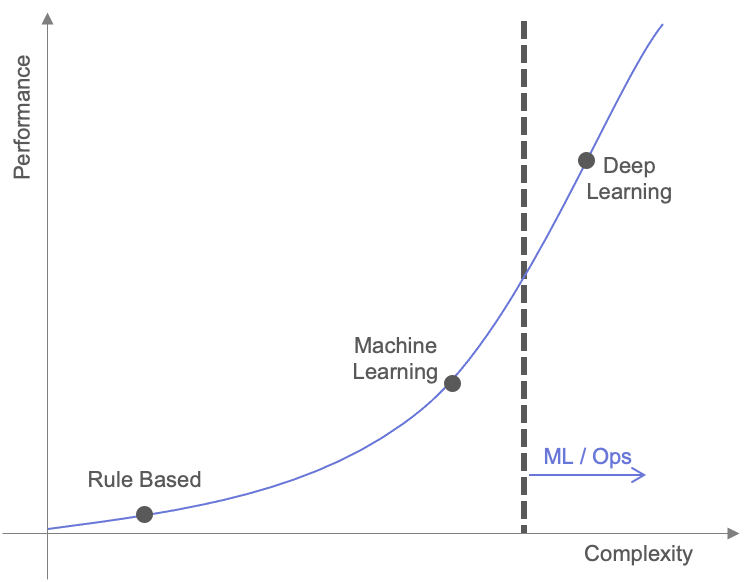
위에서 설명한 것을 x축을 모델의 복잡도, y축을 모델의 성능으로 두고 그래프로 표현한다면 다음과 같이 복잡도가 올라갈 때 모델의 성능이 올라가는 상승 관계를 갖습니다. 머신러닝에서 딥러닝으로 넘어갈 머신러닝 팀이 새로 생기게 됩니다.
만약 관리해야할 모델이 적다면 서로 협업을 통해서 충분히 해결할 수 있지만 개발해야 할 모델이 많아진다면 DevOps의 경우와 같이 사일로 현상이 나타나게 됩니다.
DevOps의 목표와 맞춰서 생각해보면 MLOps의 목표는 개발한 모델이 정상적으로 배포될 수 있는지 테스트하는 것입니다. 개발팀에서 개발한 기능이 정상적으로 배포될 수 있는지 확인하는 것이 DevOps의 목표였다면, MLOps의 목표는 머신러닝 팀에서 개발한 모델이 정상적으로 배포될 수 있는지 확인하는 것입니다.
2) ML -> Ops
하지만 최근 나오고 있는 MLOps 관련 제품과 설명을 보면 꼭 앞에서 설명한 목표만을 대상으로 하고 있지 않습니다. 어떤 경우에는 머신러닝 팀에서 만든 모델을 이용해 직접 운영을 할 수 있도록 도와주려고 합니다. 이러한 니즈는 최근 머신러닝 프로젝트가 진행되는 과정에서 알 수 있습니다.
추천시스템의 경우 운영에서 간단한 모델부터 시작해 운영할 수 있었습니다. 하지만 자연어, 이미지와 같은 곳에서는 규칙 기반의 모델보다는 딥러닝을 이용해 주어진 태스크를 해결할 수 있는지 검증(POC)를 선행하는 경우가 많습니다. 검증이 끝난 프로젝트는 이제 서비스를 위한 운영 환경을 개발하기 시작합니다. 하지만 머신러닝 팀 내의 자체 역량으로는 이 문제를 해결하기 쉽지 않습니다. 이를 해결하기 위해서 MLOps가 필요한 경우도 있습니다.
3) 결론
요약하자면 MLOps는 두 가지 목표가 있습니다. 앞에서 설명한 MLOps는 ML+Ops 로 두 팀의 생산성 향상을 위한 것이였습니다. 반면, 뒤에서 설명한 것은 ML->Ops 로 머신러닝 팀에서 직접 운영을 할 수 있도록 도와주는 것을 말합니다.