4. Why Kubernetes?
MLOps & Kubernetes
그렇다면 MLOps를 이야기할 때, 쿠버네티스(Kubernetes)라는 단어가 항상 함께 들리는 이유가 무엇일까요?
성공적인 MLOps 시스템을 구축하기 위해서는 MLOps의 구성요소 에서 설명한 것처럼 다양한 구성 요소들이 필요하지만, 각각의 구성 요소들이 유기적으로 운영되기 위해서는 인프라 레벨에서 수많은 이슈를 해결해야 합니다.
간단하게는 수많은 머신러닝 모델의 학습 요청을 차례대로 실행하는 것, 다른 작업 공간에서도 같은 실행 환경을 보장해야 하는 것, 배포된 서비스에 장애가 생겼을 때 빠르게 대응해야 하는 것 등의 이슈 등을 생각해볼 수 있습니다.
여기서 컨테이너(Container)와 컨테이너 오케스트레이션 시스템(Container Orchestration System)의 필요성이 등장합니다.
쿠버네티스와 같은 컨테이너 오케스트레이션 시스템을 도입하면 실행 환경의 격리와 관리를 효율적으로 수행할 수 있습니다. 컨테이너 오케스트레이션 시스템을 도입한다면, 머신러닝 모델을 개발하고 배포하는 과정에서 다수의 개발자가 소수의 클러스터를 공유하면서 '1번 클러스터 사용 중이신가요?', 'GPU 사용 중이던 제 프로세스 누가 죽였나요?', '누가 클러스터에 x 패키지 업데이트했나요?' 와 같은 상황을 방지할 수 있습니다.
Container
그렇다면 컨테이너란 무엇일까요? 마이크로소프트에서는 컨테이너를 다음과 같이 정의하고 있습니다.
컨테이너란 : 애플리케이션의 표준화된 이식 가능한 패키징
그런데 왜 머신러닝에서 컨테이너가 필요할까요? 머신러닝 모델들은 운영체제나 Python 실행 환경, 패키지 버전 등에 따라 다르게 동작할 수 있습니다.
이를 방지하기 위해서 머신러닝에 사용된 소스 코드와 함께 종속적인 실행 환경 전체를 하나로 묶어서(패키징해서) 공유하고 실행하는 데 활용할 수 있는 기술이 컨테이너라이제이션(Containerization) 기술입니다.
이렇게 패키징된 형태를 컨테이너 이미지라고 부르며, 컨테이너 이미지를 공유함으로써 사용자들은 어떤 시스템에서든 같은 실행 결과를 보장할 수 있게 됩니다.
즉, 단순히 Jupyter Notebook 파일이나, 모델의 소스 코드와 requirements.txt 파일을 공유하는 것이 아닌, 모든 실행 환경이 담긴 컨테이너 이미지를 공유한다면 "제 노트북에서는 잘 되는데요?" 와 같은 상황을 피할 수 있습니다.
컨테이너를 처음 접하시는 분들이 흔히 하시는 오해 중 하나는 "컨테이너 == 도커"라고 받아들이는 것입니다.
도커는 컨테이너와 같은 의미를 지니는 개념이 아니라, 컨테이너를 띄우거나, 컨테이너 이미지를 만들고 공유하는 것과 같이 컨테이너를 더욱더 쉽고 유연하게 사용할 수 있는 기능을 제공해주는 도구입니다. 정리하자면 컨테이너는 가상화 기술이고, 도커는 가상화 기술의 구현체라고 말할 수 있습니다.
다만, 도커는 여러 컨테이너 가상화 도구 중에서 쉬운 사용성과 높은 효율성을 바탕으로 가장 빠르게 성장하여 대세가 되었기에 컨테이너하면 도커라는 이미지가 자동으로 떠오르게 되었습니다. 이렇게 컨테이너와 도커 생태계가 대세가 되기까지는 다양한 이유가 있지만, 기술적으로 자세한 이야기는 모두의 MLOps의 범위를 넘어서기 때문에 다루지는 않겠습니다.
컨테이너 혹은 도커를 처음 들어보시는 분들에게는 모두의 MLOps의 내용이 다소 어렵게 느껴질 수 있으므로, 생활코딩, subicura 님의 개인 블로그 글 등의 자료를 먼저 살펴보는 것을 권장합니다.
Container Orchestration System
그렇다면 컨테이너 오케스트레이션 시스템은 무엇일까요? 오케스트레이션이라는 단어에서 추측해 볼 수 있듯이, 수많은 컨테이너가 있을 때 컨테이너들이 서로 조화롭게 구동될 수 있도록 지휘하는 시스템에 비유할 수 있습니다.
컨테이너 기반의 시스템에서 서비스는 컨테이너의 형태로 사용자들에게 제공됩니다. 이때 관리해야 할 컨테이너의 수가 적다면 운영 담당자 한 명이서도 충분히 모든 상황에 대응할 수 있습니다.
하지만, 수백 개 이상의 컨테이너가 수 십 대 이상의 클러스터에서 구동되고 있고 장애를 일으키지 않고 항상 정상 동작해야 한다면, 모든 서비스의 정상 동작 여부를 담당자 한 명이 파악하고 이슈에 대응하는 것은 불가능에 가깝습니다.
예를 들면, 모든 서비스가 정상적으로 동작하고 있는지를 계속해서 모니터링(Monitoring)해야 합니다.
만약, 특정 서비스가 장애를 일으켰다면 여러 컨테이너의 로그를 확인해가며 문제를 파악해야 합니다.
또한, 특정 클러스터나 특정 컨테이너에 작업이 몰리지 않도록 스케줄링(Scheduling)하고 로드 밸런싱(Load Balancing)하며, 스케일링(Scaling)하는 등의 수많은 작업을 담당해야 합니다.
이렇게 수많은 컨테이너의 상태를 지속해서 관리하고 운영하는 과정을 조금이나마 쉽게, 자동으로 할 수 있는 기능을 제공해주는 소프트웨어가 바로 컨테이너 오케스트레이션 시스템입니다.
머신러닝에서는 어떻게 쓰일 수 있을까요?
예를 들어서 GPU가 있어야 하는 딥러닝 학습 코드가 패키징된 컨테이너는 사용 가능한 GPU가 있는 클러스터에서 수행하고, 많은 메모리를 필요로 하는 데이터 전처리 코드가 패키징된 컨테이너는 메모리의 여유가 많은 클러스터에서 수행하고, 학습 중에 클러스터에 문제가 생기면 자동으로 같은 컨테이너를 다른 클러스터로 이동시키고 다시 학습을 진행하는 등의 작업을 사람이 일일이 수행하지 않고, 자동으로 관리하는 시스템을 개발한 뒤 맡기는 것입니다.
집필을 하는 2022년을 기준으로 쿠버네티스는 컨테이너 오케스트레이션 시스템의 사실상의 표준(De facto standard)입니다.
CNCF에서 2018년 발표한 Survey 에 따르면 다음 그림과 같이 이미 두각을 나타내고 있었으며, 2019년 발표한 Survey에 따르면 그중 78%가 상용 수준(Production Level)에서 사용하고 있다는 것을 알 수 있습니다.
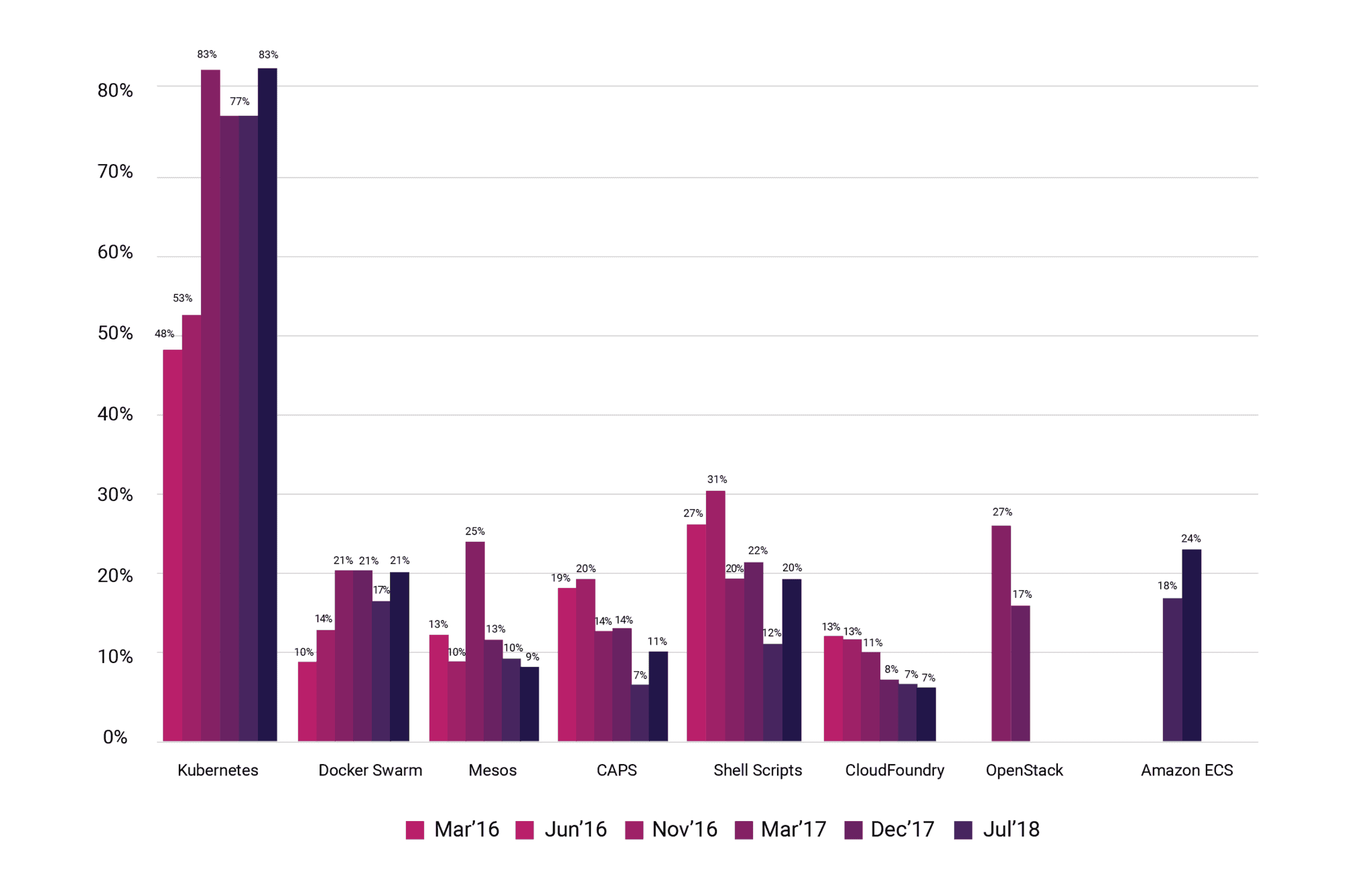
쿠버네티스 생태계가 이처럼 커지게 된 이유에는 여러 가지 이유가 있습니다. 하지만 도커와 마찬가지로 쿠버네티스 역시 머신러닝 기반의 서비스에서만 사용하는 기술이 아니기에, 자세히 다루기에는 상당히 많은 양의 기술적인 내용을 다루어야 하므로 이번 모두의 MLOps에서는 자세한 내용은 생략할 예정입니다.
다만, 모두의 MLOps에서 앞으로 다룰 내용은 도커와 쿠버네티스에 대한 내용을 어느 정도 알고 계신 분들을 대상으로 작성하였습니다. 따라서 쿠버네티스에 대해 익숙하지 않으신 분들은 다음 쿠버네티스 공식 문서, subicura 님의 개인 블로그 글 등의 쉽고 자세한 자료들을 먼저 참고해주시는 것을 권장합니다.