3. Components of MLOps
Practitioners guide to MLOps
2021년 5월에 발표된 구글의 white paper : Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning에서는 MLOps의 핵심 기능들로 다음과 같은 것들을 언급하였습니다.
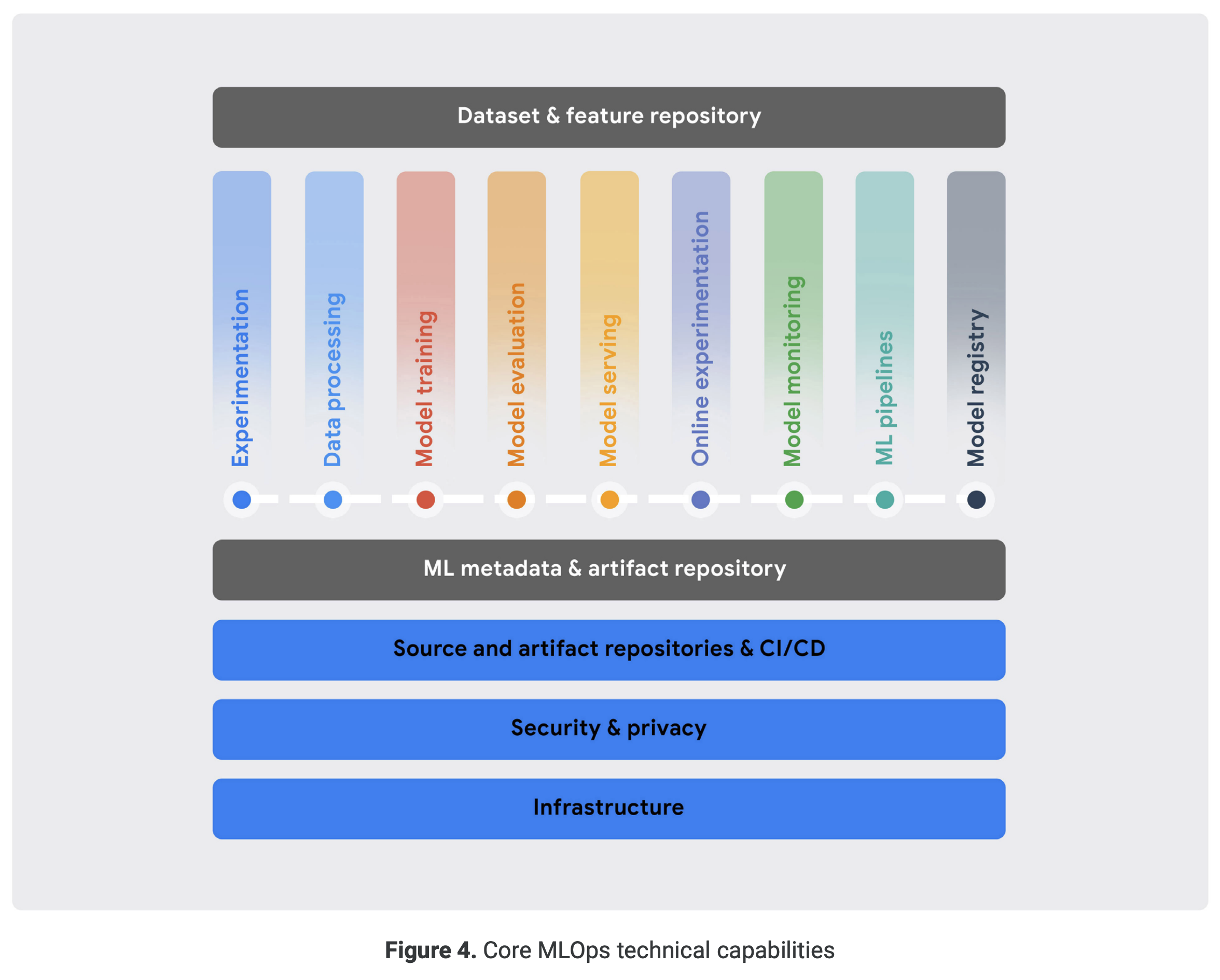
각 기능이 어떤 역할을 하는지 살펴보겠습니다.
1. Experimentation
실험(Experimentation)은 머신러닝 엔지니어들이 데이터를 분석하고, 프로토타입 모델을 만들며 학습 기능을 구현할 수 있도록 하는 다음과 같은 기능을 제공합니다.
- 깃(Git)과 같은 버전 컨트롤 도구와 통합된 노트북(Jupyter Notebook) 환경 제공
- 사용한 데이터, 하이퍼 파라미터, 평가 지표를 포함한 실험 추적 기능 제공
- 데이터와 모델에 대한 분석 및 시각화 기능 제공
2. Data Processing
데이터 처리(Data Processing)는 머신러닝 모델 개발 단계, 지속적인 학습(Continuous Training) 단계, 그리고 API 배포(API Deployment) 단계에서 많은 양의 데이터를 사용할 수 있게 해 주는 다음과 같은 기능을 제공합니다.
- 다양한 데이터 소스와 서비스에 호환되는 데이터 커넥터(connector) 기능 제공
- 다양한 형태의 데이터와 호환되는 데이터 인코더(encoder) & 디코더(decoder) 기능 제공
- 다양한 형태의 데이터에 대한 데이터 변환과 피처 엔지니어링(feature engineering) 기능 제공
- 학습과 서빙을 위한 확장 가능한 배치, 스트림 데이터 처리 기능 제공
3. Model training
모델 학습(Model training)은 모델 학습을 위한 알고리즘을 효율적으로 실행시켜주는 다음과 같은 기능을 제공합니다.
- ML 프레임워크의 실행을 위한 환경 제공
- 다수의 GPU / 분산 학습 사용을 위한 분산 학습 환경 제공
- 하이퍼 파라미터 튜닝과 최적화 기능 제공
4. Model evaluation
모델 평가(Model evaluation)는 실험 환경과 상용 환경에서 동작하는 모델의 성능을 관찰할 수 있는 다음과 같은 기능을 제공합니다.
- 평가 데이터에 대한 모델 성능 평가 기능
- 서로 다른 지속 학습 실행 결과에 대한 예측 성능 추적
- 서로 다른 모델의 성능 비교와 시각화
- 해석할 수 있는 AI 기술을 이용한 모델 출력 해석 기능 제공
5. Model serving
모델 서빙(Model serving)은 상용 환경에 모델을 배포하고 서빙하기 위한 다음과 같은 기능들을 제공합니다.
- 저 지연 추론과 고가용성 추론 기능 제공
- 다양한 ML 모델 서빙 프레임워크 지원(Tensorflow Serving, TorchServe, NVIDIA Triton, Scikit-learn, XGBoost. etc)
- 복잡한 형태의 추론 루틴 기능 제공, 예를 들어 전처리(preprocess) 또는 후처리(postprocess) 기능과 최종 결과를 위해 다수의 모델이 사용되는 경우를 말합니다.
- 순간적으로 치솟는 추론 요청을 처리하기 위한 오토 스케일링(autoscaling) 기능 제공
- 추론 요청과 추론 결과에 대한 로깅 기능 제공
6. Online experimentation
온라인 실험(Online experimentation)은 새로운 모델이 생성되었을 때, 이 모델을 배포하면 어느 정도의 성능을 보일 것인지 검증하는 기능을 제공합니다. 이 기능은 새 모델을 배포하는 것까지 연동하기 위해 모델 저장소(Model Registry)와 연동되어야 합니다.
- 카나리(canary) & 섀도(shadow) 배포 기능 제공
- A/B 테스트 기능 제공
- 멀티 암드 밴딧(Multi-armed bandit) 테스트 기능 제공
7. Model Monitoring
모델 모니터링(Model Monitoring)은 상용 환경에 배포된 모델이 정상적으로 동작하고 있는지를 모니터링하는 기능을 제공합니다. 예를 들어 모델의 성능이 떨어져 업데이트가 필요한지에 대한 정보 등을 제공합니다.
8. ML Pipeline
머신러닝 파이프라인(ML Pipeline)은 상용 환경에서 복잡한 ML 학습과 추론 작업을 구성하고 제어하고 자동화하기 위한 다음과 같은 기능을 제공합니다.
- 다양한 이벤트를 소스를 통한 파이프라인 실행 기능
- 파이프라인 파라미터와 생성되는 산출물 관리를 위한 머신러닝 메타데이터 추적과 연동 기능
- 일반적인 머신러닝 작업을 위한 내장 컴포넌트 지원과 사용자가 직접 구현한 컴포넌트에 대한 지원 기능
- 서로 다른 실행 환경 제공 기능
9. Model Registry
모델 저장소(Model Registry)는 머신러닝 모델의 생명 주기(Lifecycle)을 중앙 저장소에서 관리할 수 있게 해 주는 기능을 제공합니다.
- 학습된 모델 그리고 배포된 모델에 대한 등록, 추적, 버저닝 기능 제공
- 배포를 위해 필요한 데이터와 런타임 패키지들에 대한 정보 저장 기능
10. Dataset and Feature Repository
- 데이터에 대한 공유, 검색, 재사용 그리고 버전 관리 기능
- 이벤트 스트리밍 및 온라인 추론 작업에 대한 실시간 처리 및 저 지연 서빙 기능
- 사진, 텍스트, 테이블 형태의 데이터와 같은 다양한 형태의 데이터 지원 기능
11. ML Metadata and Artifact Tracking
MLOps의 각 단계에서는 다양한 형태의 산출물들이 생성됩니다. ML 메타데이터는 이런 산출물들에 대한 정보를 의미합니다. ML 메타데이터와 산출물 관리는 산출물의 위치, 타입, 속성, 그리고 관련된 실험(experiment)에 대한 정보를 관리하기 위해 다음과 같은 기능들을 제공합니다.
- ML 산출물에 대한 히스토리 관리 기능
- 실험과 파이프라인 파라미터 설정에 대한 추적, 공유 기능
- ML 산출물에 대한 저장, 접근, 시각화, 다운로드 기능 제공
- 다른 MLOps 기능과의 통합 기능 제공