3. Components of MLOps
Practitioners guide to MLOps
Google's white paper [Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning] published in May 2021 mentions the following core functionalities of MLOps:
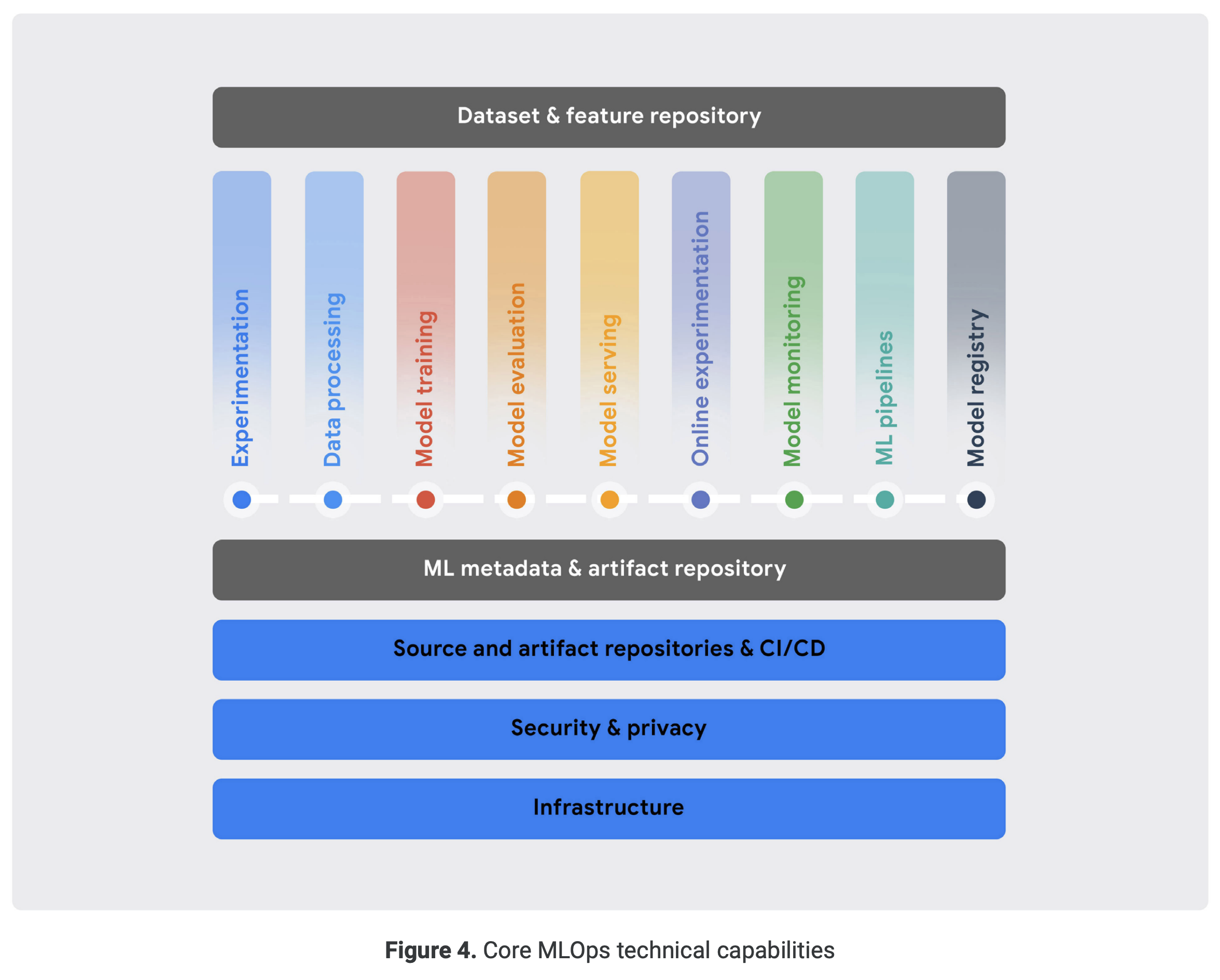
Let's look at what each feature does.
1. Experimentation
Experimentation provides machine learning engineers with the following capabilities for data analysis, prototyping model development, and implementing training functionality:
- Integration with version control tools like Git and a notebook (Jupyter Notebook) environment
- Experiment tracking capabilities including data used, hyperparameters, and evaluation metrics
- Data and model analysis and visualization capabilities
2. Data Processing
Data Processing enables working with large volumes of data during the stages of model development, continuous training, and API deployment by providing the following functionalities:
- Data connectors compatible with various data sources and services
- Data encoders and decoders compatible with different data formats
- Data transformation and feature engineering capabilities for different data types
- Scalable batch and streaming data processing capabilities for training and serving
3. Model Training
Model Training offers functionalities to efficiently execute algorithms for model training:
- Environment provisioning for ML framework execution
- Distributed training environment for multiple GPUs and distributed training
- Hyperparameter tuning and optimization capabilities
4. Model Evaluation
Model evaluation provides the following capabilities to observe the performance of models in both experimental and production environments:
- Model performance evaluation on evaluation datasets
- Tracking prediction performance across different continuous training runs
- Comparison and visualization of performance between different models
- Model output interpretation using interpretable AI techniques
5. Model Serving
Model serving offers functionalities to deploy and serve models in production environments:
- Low-latency and high-availability inference capabilities
- Support for various ML model serving frameworks (TensorFlow Serving, TorchServe, NVIDIA Triton, Scikit-learn, XGBoost, etc.)
- Advanced inference routines, such as preprocessing or postprocessing, and multi-model ensembling for final results
- Autoscaling capabilities to handle spiking inference requests
- Logging of inference requests and results
6. Online Experimentation
Online experimentation provides capabilities to validate the performance of newly generated models when deployed. This functionality should be integrated with a Model Registry to coordinate the deployment of new models.
- Canary and shadow deployment features
- A/B testing capabilities
- Multi-armed bandit testing functionality
7. Model Monitoring
Model monitoring enables the monitoring of deployed models in production environments to ensure proper functioning and provides information on model performance degradation and the need for updates.
8. ML Pipeline
ML Pipeline offers the following functionalities to configure, control, and automate complex ML training and inference workflows in production environments:
- Pipeline execution through various event sources
- ML metadata tracking and integration for pipeline parameter and artifact management
- Support for built-in components for common ML tasks and user-defined components
- Provisioning of different execution environments
9. Model Registry
The Model Registry provides the capability to manage the lifecycle of machine learning models in a centralized repository.
- Registration, tracking, and versioning of trained and deployed models
- Storage of information about the required data and runtime packages for deployment
10. Dataset and Feature Repository
- Sharing, search, reuse, and versioning capabilities for datasets
- Real-time processing and low-latency serving capabilities for event streaming and online inference tasks
- Support for various types of data, such as images, text, and tabular data
11. ML Metadata and Artifact Tracking
In each stage of MLOps, various artifacts are generated. ML metadata refers to the information about these artifacts. ML metadata and artifact management provide the following functionalities to manage the location, type, attributes, and associations with experiments:
- History management for ML artifacts
- Tracking and sharing of experiments and pipeline parameter configurations
- Storage, access, visualization, and download capabilities for ML artifacts
- Integration with other MLOps functionalities