12. Component - MLFlow
MLFlow Component
Advanced Usage Component 에서 학습한 모델이 API Deployment까지 이어지기 위해서는 MLFlow에 모델을 저장해야 합니다.
이번 페이지에서는 MLFlow에 모델을 저장할 수 있는 컴포넌트를 작성하는 과정을 설명합니다.
MLFlow in Local
MLFlow에서 모델을 저장하고 서빙에서 사용하기 위해서는 다음의 항목들이 필요합니다.
- model
- signature
- input_example
- conda_env
파이썬 코드를 통해서 MLFLow에 모델을 저장하는 과정에 대해서 알아보겠습니다.
1. 모델 학습
아래 과정은 iris 데이터를 이용해 SVC 모델을 학습하는 과정입니다.
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.svm import SVC
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
clf = SVC(kernel="rbf")
clf.fit(data, target)
2. MLFLow Infos
mlflow에 필요한 정보들을 만드는 과정입니다.
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
input_example = data.sample(1)
signature = infer_signature(data, clf.predict(data))
conda_env = _mlflow_conda_env(additional_pip_deps=["dill", "pandas", "scikit-learn"])
각 변수의 내용을 확인하면 다음과 같습니다.
input_examplesepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 6.5 6.7 3.1 4.4 signatureinputs:
['sepal length (cm)': double, 'sepal width (cm)': double, 'petal length (cm)': double, 'petal width (cm)': double]
outputs:
[Tensor('int64', (-1,))]conda_env{'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': ['python=3.8.10',
'pip',
{'pip': ['mlflow', 'dill', 'pandas', 'scikit-learn']}]}
3. Save MLFLow Infos
다음으로 학습한 정보들과 모델을 저장합니다.
학습한 모델이 sklearn 패키지를 이용하기 때문에 mlflow.sklearn 을 이용하면 쉽게 모델을 저장할 수 있습니다.
from mlflow.sklearn import save_model
save_model(
sk_model=clf,
path="svc",
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
로컬에서 작업하면 다음과 같은 svc 폴더가 생기며 아래와 같은 파일들이 생성됩니다.
ls svc
위의 명령어를 실행하면 다음의 출력값을 확인할 수 있습니다.
MLmodel conda.yaml input_example.json model.pkl requirements.txt
각 파일을 확인하면 다음과 같습니다.
MLmodel
flavors:
python_function:
env: conda.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
python_version: 3.8.10
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 1.0.1
saved_input_example_info:
artifact_path: input_example.json
pandas_orient: split
type: dataframe
signature:
inputs: '[{"name": "sepal length (cm)", "type": "double"}, {"name": "sepal width
(cm)", "type": "double"}, {"name": "petal length (cm)", "type": "double"}, {"name":
"petal width (cm)", "type": "double"}]'
outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "int64", "shape": [-1]}}]'
utc_time_created: '2021-12-06 06:52:30.612810'conda.yaml
channels:
- conda-forge
dependencies:
- python=3.8.10
- pip
- pip:
- mlflow
- dill
- pandas
- scikit-learn
name: mlflow-envinput_example.json
{
"columns":
[
"sepal length (cm)",
"sepal width (cm)",
"petal length (cm)",
"petal width (cm)"
],
"data":
[
[6.7, 3.1, 4.4, 1.4]
]
}requirements.txt
mlflow
dill
pandas
scikit-learnmodel.pkl
MLFlow on Server
이제 저장된 모델을 mlflow 서버에 올리는 작업을 해보겠습니다.
import mlflow
with mlflow.start_run():
mlflow.log_artifact("svc/")
저장하고 mlruns 가 생성된 경로에서 mlflow ui 명령어를 이용해 mlflow 서버와 대시보드를 띄웁니다.
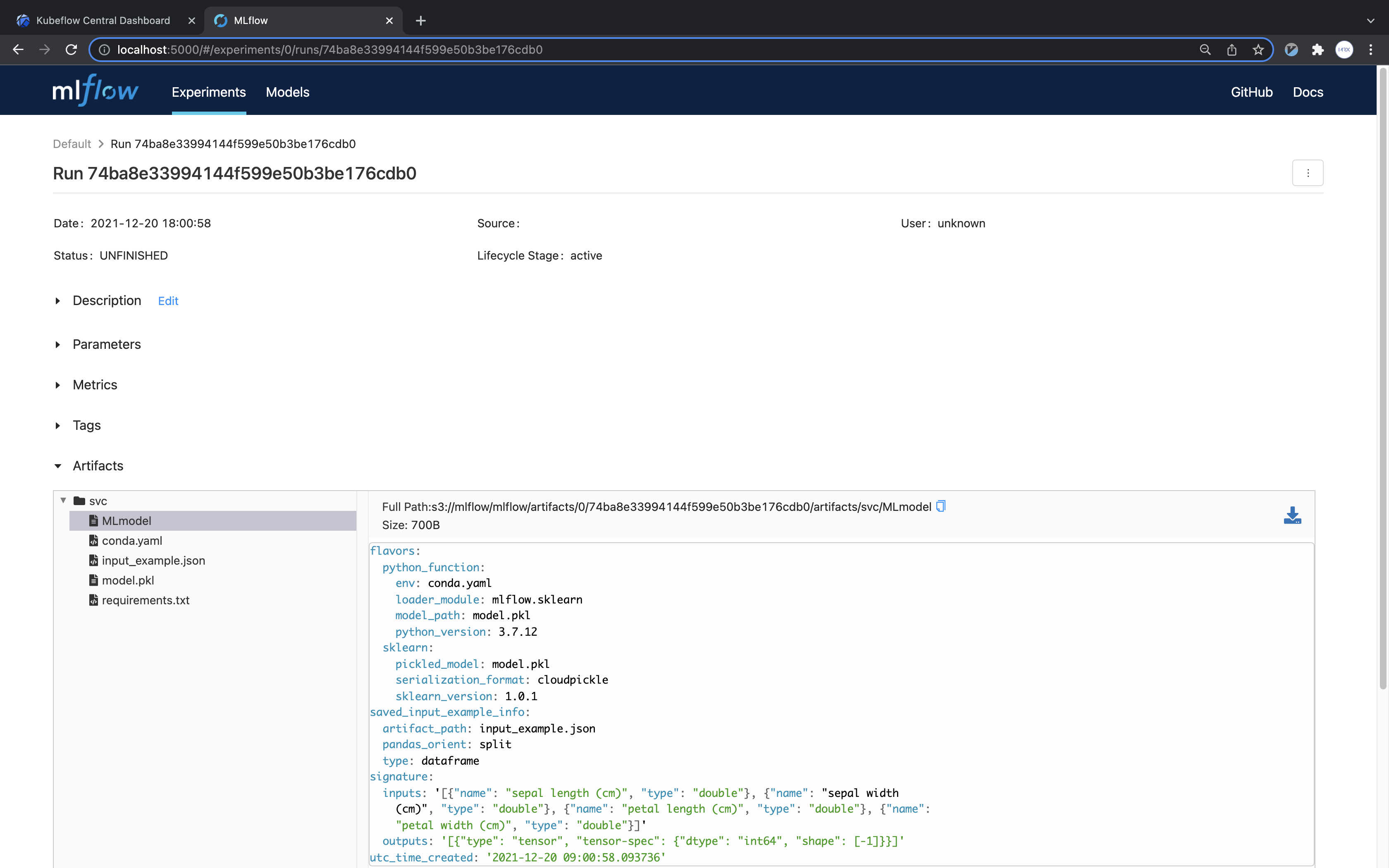
mlflow 대시보드에 접속하여 생성된 run을 클릭하면 다음과 같이 보입니다.
 (해당 화면은 mlflow 버전에 따라 다를 수 있습니다.)
(해당 화면은 mlflow 버전에 따라 다를 수 있습니다.)
MLFlow Component
이제 Kubeflow에서 재사용할 수 있는 컴포넌트를 작성해 보겠습니다.
재사용할 수 있는 컴포넌트를 작성하는 방법은 크게 3가지가 있습니다.
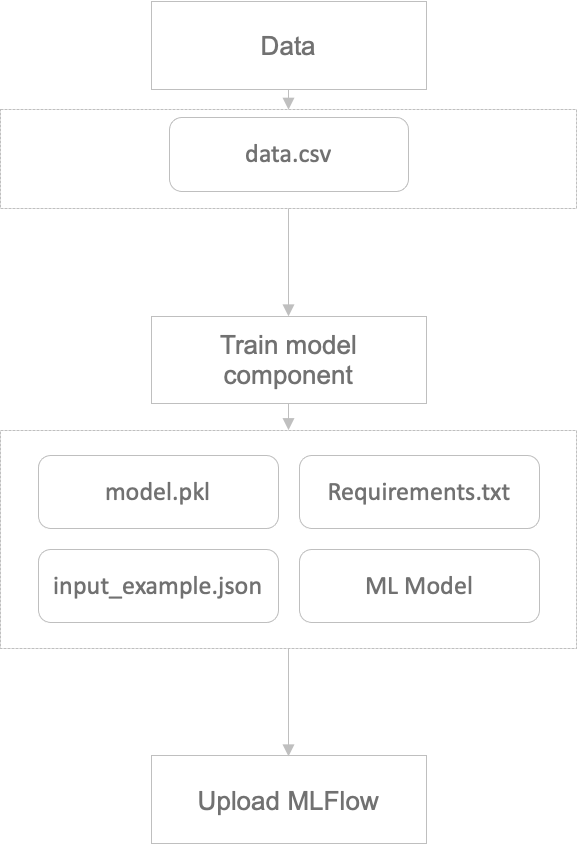
모델을 학습하는 컴포넌트에서 필요한 환경을 저장 후 MLFlow 컴포넌트는 업로드만 담당
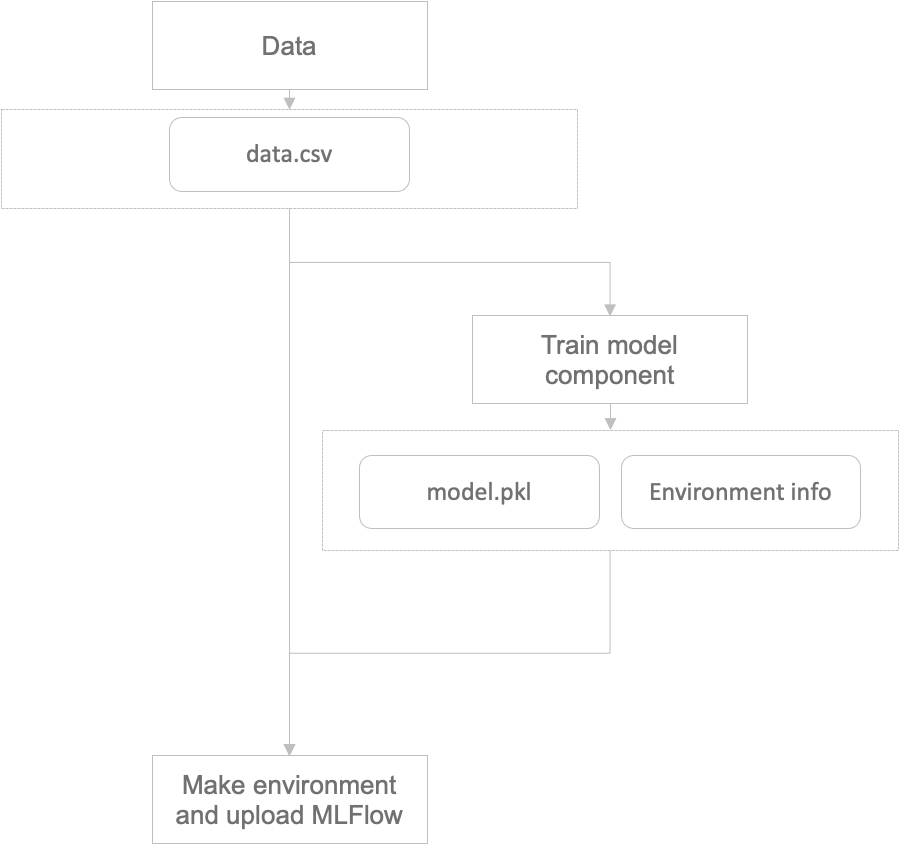
학습된 모델과 데이터를 MLFlow 컴포넌트에 전달 후 컴포넌트에서 저장과 업로드 담당
모델을 학습하는 컴포넌트에서 저장과 업로드를 담당
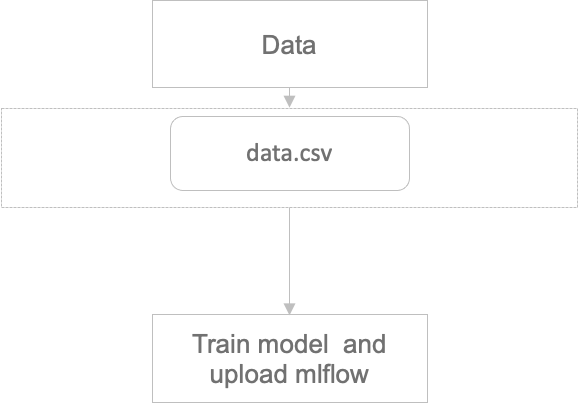
저희는 이 중 1번의 접근 방법을 통해 모델을 관리하려고 합니다. 이유는 MLFlow 모델을 업로드하는 코드는 바뀌지 않기 때문에 매번 3번처럼 컴포넌트 작성마다 작성할 필요는 없기 때문입니다.
컴포넌트를 재활용하는 방법은 1번과 2번의 방법으로 가능합니다. 다만 2번의 경우 모델이 학습된 이미지와 패키지들을 전달해야 하므로 결국 컴포넌트에 대한 추가 정보를 전달해야 합니다.
1번의 방법으로 진행하기 위해서는 학습하는 컴포넌트 또한 변경되어야 합니다. 모델을 저장하는데 필요한 환경들을 저장해주는 코드가 추가되어야 합니다.
from functools import partial
from kfp.components import InputPath, OutputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
input_example_path: OutputPath("dill"),
signature_path: OutputPath("dill"),
conda_env_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)
그리고 MLFlow에 업로드하는 컴포넌트를 작성합니다.
이 때 업로드되는 MLflow의 endpoint를 우리가 설치한 mlflow service 로 이어지게 설정해주어야 합니다.
이 때 S3 Endpoint의 주소는 MLflow Server 설치 당시 설치한 minio의 쿠버네티스 서비스 DNS 네임을 활용합니다. 해당 service 는 kubeflow namespace에서 minio-service라는 이름으로 생성되었으므로, http://minio-service.kubeflow.svc:9000 로 설정합니다.
이와 비슷하게 tracking_uri의 주소는 mlflow server의 쿠버네티스 서비스 DNS 네임을 활용하여, http://mlflow-server-service.mlflow-system.svc:5000 로 설정합니다.
from functools import partial
from kfp.components import InputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow", "boto3"],
)
def upload_sklearn_model_to_mlflow(
model_name: str,
model_path: InputPath("dill"),
input_example_path: InputPath("dill"),
signature_path: InputPath("dill"),
conda_env_path: InputPath("dill"),
):
import os
import dill
from mlflow.sklearn import save_model
from mlflow.tracking.client import MlflowClient
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio-service.kubeflow.svc:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
client = MlflowClient("http://mlflow-server-service.mlflow-system.svc:5000")
with open(model_path, mode="rb") as file_reader:
clf = dill.load(file_reader)
with open(input_example_path, "rb") as file_reader:
input_example = dill.load(file_reader)
with open(signature_path, "rb") as file_reader:
signature = dill.load(file_reader)
with open(conda_env_path, "rb") as file_reader:
conda_env = dill.load(file_reader)
save_model(
sk_model=clf,
path=model_name,
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
run = client.create_run(experiment_id="0")
client.log_artifact(run.info.run_id, model_name)
MLFlow Pipeline
이제 작성한 컴포넌트들을 연결해서 파이프라인으로 만들어 보겠습니다.
Data Component
모델을 학습할 때 쓸 데이터는 sklearn의 iris 입니다. 데이터를 생성하는 컴포넌트를 작성합니다.
from functools import partial
from kfp.components import InputPath, OutputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["pandas", "scikit-learn"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
Pipeline
파이프라인 코드는 다음과 같이 작성할 수 있습니다.
from kfp.dsl import pipeline
@pipeline(name="mlflow_pipeline")
def mlflow_pipeline(kernel: str, model_name: str):
iris_data = load_iris_data()
model = train_from_csv(
train_data=iris_data.outputs["data"],
train_target=iris_data.outputs["target"],
kernel=kernel,
)
_ = upload_sklearn_model_to_mlflow(
model_name=model_name,
model=model.outputs["model"],
input_example=model.outputs["input_example"],
signature=model.outputs["signature"],
conda_env=model.outputs["conda_env"],
)
Run
위에서 작성된 컴포넌트와 파이프라인을 하나의 파이썬 파일에 정리하면 다음과 같습니다.
from functools import partial
import kfp
from kfp.components import InputPath, OutputPath, create_component_from_func
from kfp.dsl import pipeline
@partial(
create_component_from_func,
packages_to_install=["pandas", "scikit-learn"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
input_example_path: OutputPath("dill"),
signature_path: OutputPath("dill"),
conda_env_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow", "boto3"],
)
def upload_sklearn_model_to_mlflow(
model_name: str,
model_path: InputPath("dill"),
input_example_path: InputPath("dill"),
signature_path: InputPath("dill"),
conda_env_path: InputPath("dill"),
):
import os
import dill
from mlflow.sklearn import save_model
from mlflow.tracking.client import MlflowClient
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio-service.kubeflow.svc:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
client = MlflowClient("http://mlflow-server-service.mlflow-system.svc:5000")
with open(model_path, mode="rb") as file_reader:
clf = dill.load(file_reader)
with open(input_example_path, "rb") as file_reader:
input_example = dill.load(file_reader)
with open(signature_path, "rb") as file_reader:
signature = dill.load(file_reader)
with open(conda_env_path, "rb") as file_reader:
conda_env = dill.load(file_reader)
save_model(
sk_model=clf,
path=model_name,
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
run = client.create_run(experiment_id="0")
client.log_artifact(run.info.run_id, model_name)
@pipeline(name="mlflow_pipeline")
def mlflow_pipeline(kernel: str, model_name: str):
iris_data = load_iris_data()
model = train_from_csv(
train_data=iris_data.outputs["data"],
train_target=iris_data.outputs["target"],
kernel=kernel,
)
_ = upload_sklearn_model_to_mlflow(
model_name=model_name,
model=model.outputs["model"],
input_example=model.outputs["input_example"],
signature=model.outputs["signature"],
conda_env=model.outputs["conda_env"],
)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(mlflow_pipeline, "mlflow_pipeline.yaml")
mlflow_pipeline.yaml
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: mlflow-pipeline-
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.10, pipelines.kubeflow.org/pipeline_compilation_time: '2022-01-19T14:14:11.999807',
pipelines.kubeflow.org/pipeline_spec: '{"inputs": [{"name": "kernel", "type":
"String"}, {"name": "model_name", "type": "String"}], "name": "mlflow_pipeline"}'}
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.10}
spec:
entrypoint: mlflow-pipeline
templates:
- name: load-iris-data
container:
args: [--data, /tmp/outputs/data/data, --target, /tmp/outputs/target/data]
command:
- sh
- -c
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
'pandas' 'scikit-learn' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip
install --quiet --no-warn-script-location 'pandas' 'scikit-learn' --user)
&& "$0" "$@"
- sh
- -ec
- |
program_path=$(mktemp)
printf "%s" "$0" > "$program_path"
python3 -u "$program_path" "$@"
- |
def _make_parent_dirs_and_return_path(file_path: str):
import os
os.makedirs(os.path.dirname(file_path), exist_ok=True)
return file_path
def load_iris_data(
data_path,
target_path,
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
import argparse
_parser = argparse.ArgumentParser(prog='Load iris data', description='')
_parser.add_argument("--data", dest="data_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--target", dest="target_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parsed_args = vars(_parser.parse_args())
_outputs = load_iris_data(**_parsed_args)
image: python:3.7
outputs:
artifacts:
- {name: load-iris-data-data, path: /tmp/outputs/data/data}
- {name: load-iris-data-target, path: /tmp/outputs/target/data}
metadata:
labels:
pipelines.kubeflow.org/kfp_sdk_version: 1.8.10
pipelines.kubeflow.org/pipeline-sdk-type: kfp
pipelines.kubeflow.org/enable_caching: "true"
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
{"args": ["--data", {"outputPath": "data"}, "--target", {"outputPath": "target"}],
"command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip
install --quiet --no-warn-script-location ''pandas'' ''scikit-learn'' ||
PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
''pandas'' ''scikit-learn'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
"def _make_parent_dirs_and_return_path(file_path: str):\n import os\n os.makedirs(os.path.dirname(file_path),
exist_ok=True)\n return file_path\n\ndef load_iris_data(\n data_path,\n target_path,\n):\n import
pandas as pd\n from sklearn.datasets import load_iris\n\n iris = load_iris()\n\n data
= pd.DataFrame(iris[\"data\"], columns=iris[\"feature_names\"])\n target
= pd.DataFrame(iris[\"target\"], columns=[\"target\"])\n\n data.to_csv(data_path,
index=False)\n target.to_csv(target_path, index=False)\n\nimport argparse\n_parser
= argparse.ArgumentParser(prog=''Load iris data'', description='''')\n_parser.add_argument(\"--data\",
dest=\"data_path\", type=_make_parent_dirs_and_return_path, required=True,
default=argparse.SUPPRESS)\n_parser.add_argument(\"--target\", dest=\"target_path\",
type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)\n_parsed_args
= vars(_parser.parse_args())\n\n_outputs = load_iris_data(**_parsed_args)\n"],
"image": "python:3.7"}}, "name": "Load iris data", "outputs": [{"name":
"data", "type": "csv"}, {"name": "target", "type": "csv"}]}', pipelines.kubeflow.org/component_ref: '{}'}
- name: mlflow-pipeline
inputs:
parameters:
- {name: kernel}
- {name: model_name}
dag:
tasks:
- {name: load-iris-data, template: load-iris-data}
- name: train-from-csv
template: train-from-csv
dependencies: [load-iris-data]
arguments:
parameters:
- {name: kernel, value: '{{inputs.parameters.kernel}}'}
artifacts:
- {name: load-iris-data-data, from: '{{tasks.load-iris-data.outputs.artifacts.load-iris-data-data}}'}
- {name: load-iris-data-target, from: '{{tasks.load-iris-data.outputs.artifacts.load-iris-data-target}}'}
- name: upload-sklearn-model-to-mlflow
template: upload-sklearn-model-to-mlflow
dependencies: [train-from-csv]
arguments:
parameters:
- {name: model_name, value: '{{inputs.parameters.model_name}}'}
artifacts:
- {name: train-from-csv-conda_env, from: '{{tasks.train-from-csv.outputs.artifacts.train-from-csv-conda_env}}'}
- {name: train-from-csv-input_example, from: '{{tasks.train-from-csv.outputs.artifacts.train-from-csv-input_example}}'}
- {name: train-from-csv-model, from: '{{tasks.train-from-csv.outputs.artifacts.train-from-csv-model}}'}
- {name: train-from-csv-signature, from: '{{tasks.train-from-csv.outputs.artifacts.train-from-csv-signature}}'}
- name: train-from-csv
container:
args: [--train-data, /tmp/inputs/train_data/data, --train-target, /tmp/inputs/train_target/data,
--kernel, '{{inputs.parameters.kernel}}', --model, /tmp/outputs/model/data,
--input-example, /tmp/outputs/input_example/data, --signature, /tmp/outputs/signature/data,
--conda-env, /tmp/outputs/conda_env/data]
command:
- sh
- -c
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
'dill' 'pandas' 'scikit-learn' 'mlflow' || PIP_DISABLE_PIP_VERSION_CHECK=1
python3 -m pip install --quiet --no-warn-script-location 'dill' 'pandas' 'scikit-learn'
'mlflow' --user) && "$0" "$@"
- sh
- -ec
- |
program_path=$(mktemp)
printf "%s" "$0" > "$program_path"
python3 -u "$program_path" "$@"
- |
def _make_parent_dirs_and_return_path(file_path: str):
import os
os.makedirs(os.path.dirname(file_path), exist_ok=True)
return file_path
def train_from_csv(
train_data_path,
train_target_path,
model_path,
input_example_path,
signature_path,
conda_env_path,
kernel,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)
import argparse
_parser = argparse.ArgumentParser(prog='Train from csv', description='')
_parser.add_argument("--train-data", dest="train_data_path", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--train-target", dest="train_target_path", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--kernel", dest="kernel", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--model", dest="model_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--input-example", dest="input_example_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--signature", dest="signature_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--conda-env", dest="conda_env_path", type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)
_parsed_args = vars(_parser.parse_args())
_outputs = train_from_csv(**_parsed_args)
image: python:3.7
inputs:
parameters:
- {name: kernel}
artifacts:
- {name: load-iris-data-data, path: /tmp/inputs/train_data/data}
- {name: load-iris-data-target, path: /tmp/inputs/train_target/data}
outputs:
artifacts:
- {name: train-from-csv-conda_env, path: /tmp/outputs/conda_env/data}
- {name: train-from-csv-input_example, path: /tmp/outputs/input_example/data}
- {name: train-from-csv-model, path: /tmp/outputs/model/data}
- {name: train-from-csv-signature, path: /tmp/outputs/signature/data}
metadata:
labels:
pipelines.kubeflow.org/kfp_sdk_version: 1.8.10
pipelines.kubeflow.org/pipeline-sdk-type: kfp
pipelines.kubeflow.org/enable_caching: "true"
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
{"args": ["--train-data", {"inputPath": "train_data"}, "--train-target",
{"inputPath": "train_target"}, "--kernel", {"inputValue": "kernel"}, "--model",
{"outputPath": "model"}, "--input-example", {"outputPath": "input_example"},
"--signature", {"outputPath": "signature"}, "--conda-env", {"outputPath":
"conda_env"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
python3 -m pip install --quiet --no-warn-script-location ''dill'' ''pandas''
''scikit-learn'' ''mlflow'' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m
pip install --quiet --no-warn-script-location ''dill'' ''pandas'' ''scikit-learn''
''mlflow'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
"def _make_parent_dirs_and_return_path(file_path: str):\n import os\n os.makedirs(os.path.dirname(file_path),
exist_ok=True)\n return file_path\n\ndef train_from_csv(\n train_data_path,\n train_target_path,\n model_path,\n input_example_path,\n signature_path,\n conda_env_path,\n kernel,\n):\n import
dill\n import pandas as pd\n from sklearn.svm import SVC\n\n from
mlflow.models.signature import infer_signature\n from mlflow.utils.environment
import _mlflow_conda_env\n\n train_data = pd.read_csv(train_data_path)\n train_target
= pd.read_csv(train_target_path)\n\n clf = SVC(kernel=kernel)\n clf.fit(train_data,
train_target)\n\n with open(model_path, mode=\"wb\") as file_writer:\n dill.dump(clf,
file_writer)\n\n input_example = train_data.sample(1)\n with open(input_example_path,
\"wb\") as file_writer:\n dill.dump(input_example, file_writer)\n\n signature
= infer_signature(train_data, clf.predict(train_data))\n with open(signature_path,
\"wb\") as file_writer:\n dill.dump(signature, file_writer)\n\n conda_env
= _mlflow_conda_env(\n additional_pip_deps=[\"dill\", \"pandas\",
\"scikit-learn\"]\n )\n with open(conda_env_path, \"wb\") as file_writer:\n dill.dump(conda_env,
file_writer)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Train
from csv'', description='''')\n_parser.add_argument(\"--train-data\", dest=\"train_data_path\",
type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--train-target\",
dest=\"train_target_path\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--kernel\",
dest=\"kernel\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--model\",
dest=\"model_path\", type=_make_parent_dirs_and_return_path, required=True,
default=argparse.SUPPRESS)\n_parser.add_argument(\"--input-example\", dest=\"input_example_path\",
type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--signature\",
dest=\"signature_path\", type=_make_parent_dirs_and_return_path, required=True,
default=argparse.SUPPRESS)\n_parser.add_argument(\"--conda-env\", dest=\"conda_env_path\",
type=_make_parent_dirs_and_return_path, required=True, default=argparse.SUPPRESS)\n_parsed_args
= vars(_parser.parse_args())\n\n_outputs = train_from_csv(**_parsed_args)\n"],
"image": "python:3.7"}}, "inputs": [{"name": "train_data", "type": "csv"},
{"name": "train_target", "type": "csv"}, {"name": "kernel", "type": "String"}],
"name": "Train from csv", "outputs": [{"name": "model", "type": "dill"},
{"name": "input_example", "type": "dill"}, {"name": "signature", "type":
"dill"}, {"name": "conda_env", "type": "dill"}]}', pipelines.kubeflow.org/component_ref: '{}',
pipelines.kubeflow.org/arguments.parameters: '{"kernel": "{{inputs.parameters.kernel}}"}'}
- name: upload-sklearn-model-to-mlflow
container:
args: [--model-name, '{{inputs.parameters.model_name}}', --model, /tmp/inputs/model/data,
--input-example, /tmp/inputs/input_example/data, --signature, /tmp/inputs/signature/data,
--conda-env, /tmp/inputs/conda_env/data]
command:
- sh
- -c
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
'dill' 'pandas' 'scikit-learn' 'mlflow' 'boto3' || PIP_DISABLE_PIP_VERSION_CHECK=1
python3 -m pip install --quiet --no-warn-script-location 'dill' 'pandas' 'scikit-learn'
'mlflow' 'boto3' --user) && "$0" "$@"
- sh
- -ec
- |
program_path=$(mktemp)
printf "%s" "$0" > "$program_path"
python3 -u "$program_path" "$@"
- |
def upload_sklearn_model_to_mlflow(
model_name,
model_path,
input_example_path,
signature_path,
conda_env_path,
):
import os
import dill
from mlflow.sklearn import save_model
from mlflow.tracking.client import MlflowClient
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio-service.kubeflow.svc:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
client = MlflowClient("http://mlflow-server-service.mlflow-system.svc:5000")
with open(model_path, mode="rb") as file_reader:
clf = dill.load(file_reader)
with open(input_example_path, "rb") as file_reader:
input_example = dill.load(file_reader)
with open(signature_path, "rb") as file_reader:
signature = dill.load(file_reader)
with open(conda_env_path, "rb") as file_reader:
conda_env = dill.load(file_reader)
save_model(
sk_model=clf,
path=model_name,
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
run = client.create_run(experiment_id="0")
client.log_artifact(run.info.run_id, model_name)
import argparse
_parser = argparse.ArgumentParser(prog='Upload sklearn model to mlflow', description='')
_parser.add_argument("--model-name", dest="model_name", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--model", dest="model_path", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--input-example", dest="input_example_path", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--signature", dest="signature_path", type=str, required=True, default=argparse.SUPPRESS)
_parser.add_argument("--conda-env", dest="conda_env_path", type=str, required=True, default=argparse.SUPPRESS)
_parsed_args = vars(_parser.parse_args())
_outputs = upload_sklearn_model_to_mlflow(**_parsed_args)
image: python:3.7
inputs:
parameters:
- {name: model_name}
artifacts:
- {name: train-from-csv-conda_env, path: /tmp/inputs/conda_env/data}
- {name: train-from-csv-input_example, path: /tmp/inputs/input_example/data}
- {name: train-from-csv-model, path: /tmp/inputs/model/data}
- {name: train-from-csv-signature, path: /tmp/inputs/signature/data}
metadata:
labels:
pipelines.kubeflow.org/kfp_sdk_version: 1.8.10
pipelines.kubeflow.org/pipeline-sdk-type: kfp
pipelines.kubeflow.org/enable_caching: "true"
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
{"args": ["--model-name", {"inputValue": "model_name"}, "--model", {"inputPath":
"model"}, "--input-example", {"inputPath": "input_example"}, "--signature",
{"inputPath": "signature"}, "--conda-env", {"inputPath": "conda_env"}],
"command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip
install --quiet --no-warn-script-location ''dill'' ''pandas'' ''scikit-learn''
''mlflow'' ''boto3'' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
--quiet --no-warn-script-location ''dill'' ''pandas'' ''scikit-learn'' ''mlflow''
''boto3'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
"def upload_sklearn_model_to_mlflow(\n model_name,\n model_path,\n input_example_path,\n signature_path,\n conda_env_path,\n):\n import
os\n import dill\n from mlflow.sklearn import save_model\n\n from
mlflow.tracking.client import MlflowClient\n\n os.environ[\"MLFLOW_S3_ENDPOINT_URL\"]
= \"http://minio-service.kubeflow.svc:9000\"\n os.environ[\"AWS_ACCESS_KEY_ID\"]
= \"minio\"\n os.environ[\"AWS_SECRET_ACCESS_KEY\"] = \"minio123\"\n\n client
= MlflowClient(\"http://mlflow-server-service.mlflow-system.svc:5000\")\n\n with
open(model_path, mode=\"rb\") as file_reader:\n clf = dill.load(file_reader)\n\n with
open(input_example_path, \"rb\") as file_reader:\n input_example
= dill.load(file_reader)\n\n with open(signature_path, \"rb\") as file_reader:\n signature
= dill.load(file_reader)\n\n with open(conda_env_path, \"rb\") as file_reader:\n conda_env
= dill.load(file_reader)\n\n save_model(\n sk_model=clf,\n path=model_name,\n serialization_format=\"cloudpickle\",\n conda_env=conda_env,\n signature=signature,\n input_example=input_example,\n )\n run
= client.create_run(experiment_id=\"0\")\n client.log_artifact(run.info.run_id,
model_name)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Upload
sklearn model to mlflow'', description='''')\n_parser.add_argument(\"--model-name\",
dest=\"model_name\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--model\",
dest=\"model_path\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--input-example\",
dest=\"input_example_path\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--signature\",
dest=\"signature_path\", type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--conda-env\",
dest=\"conda_env_path\", type=str, required=True, default=argparse.SUPPRESS)\n_parsed_args
= vars(_parser.parse_args())\n\n_outputs = upload_sklearn_model_to_mlflow(**_parsed_args)\n"],
"image": "python:3.7"}}, "inputs": [{"name": "model_name", "type": "String"},
{"name": "model", "type": "dill"}, {"name": "input_example", "type": "dill"},
{"name": "signature", "type": "dill"}, {"name": "conda_env", "type": "dill"}],
"name": "Upload sklearn model to mlflow"}', pipelines.kubeflow.org/component_ref: '{}',
pipelines.kubeflow.org/arguments.parameters: '{"model_name": "{{inputs.parameters.model_name}}"}'}
arguments:
parameters:
- {name: kernel}
- {name: model_name}
serviceAccountName: pipeline-runner
실행후 생성된 mlflow_pipeline.yaml 파일을 파이프라인 업로드한 후, 실행하여 run 의 결과를 확인합니다.
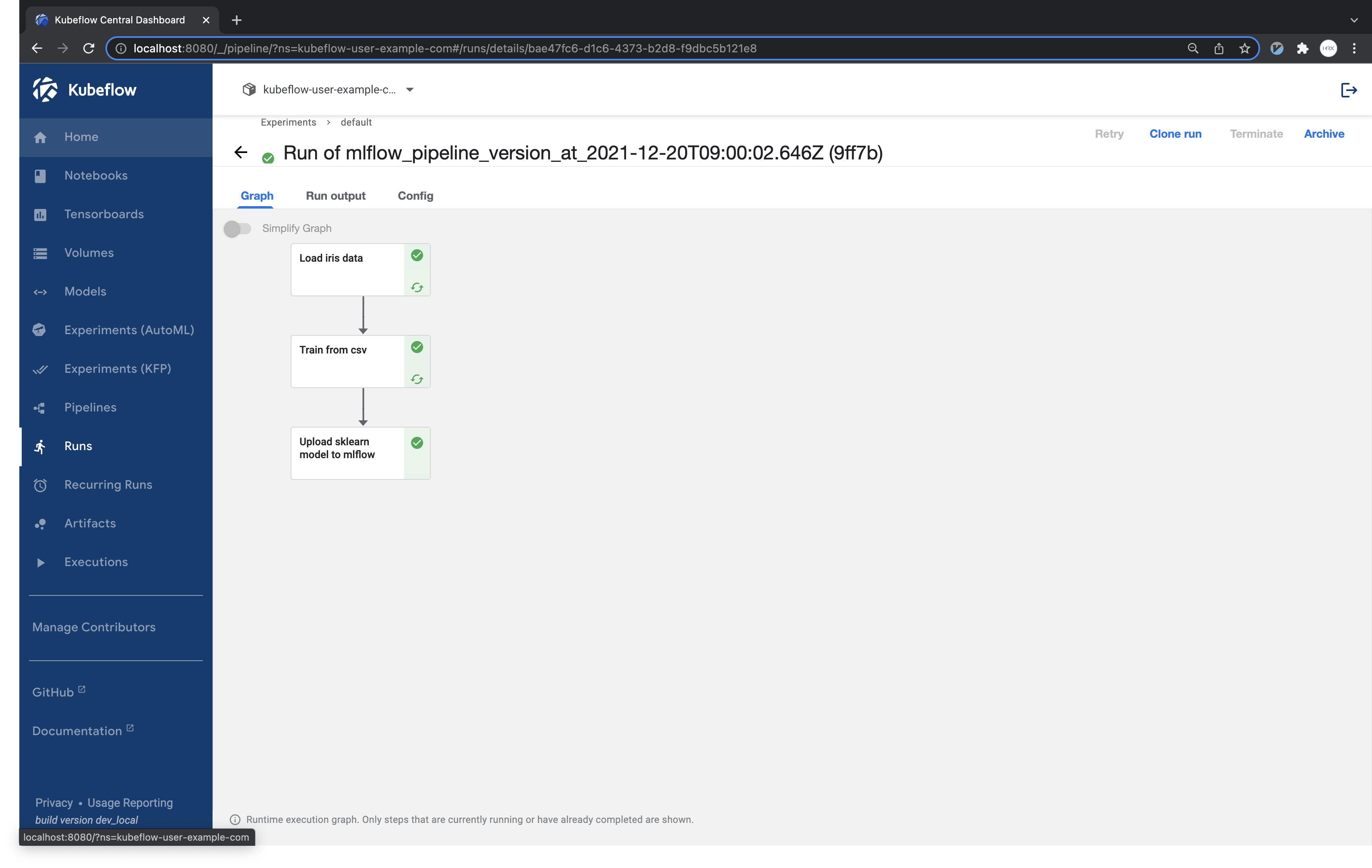
mlflow service를 포트포워딩해서 MLflow ui에 접속합니다.
kubectl port-forward svc/mlflow-server-service -n mlflow-system 5000:5000
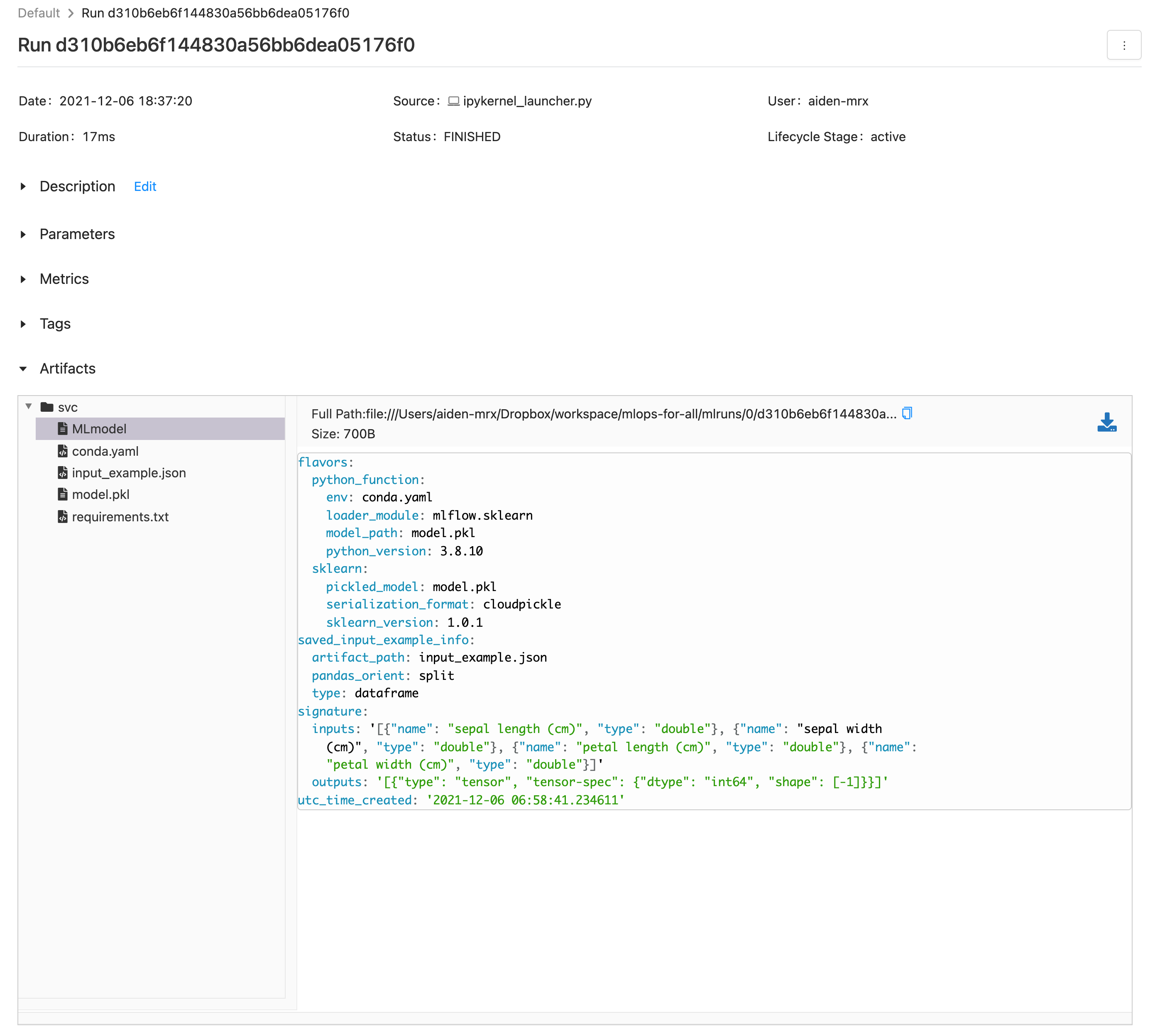
웹 브라우저를 열어 localhost:5000으로 접속하면, 다음과 같이 run이 생성된 것을 확인할 수 있습니다.
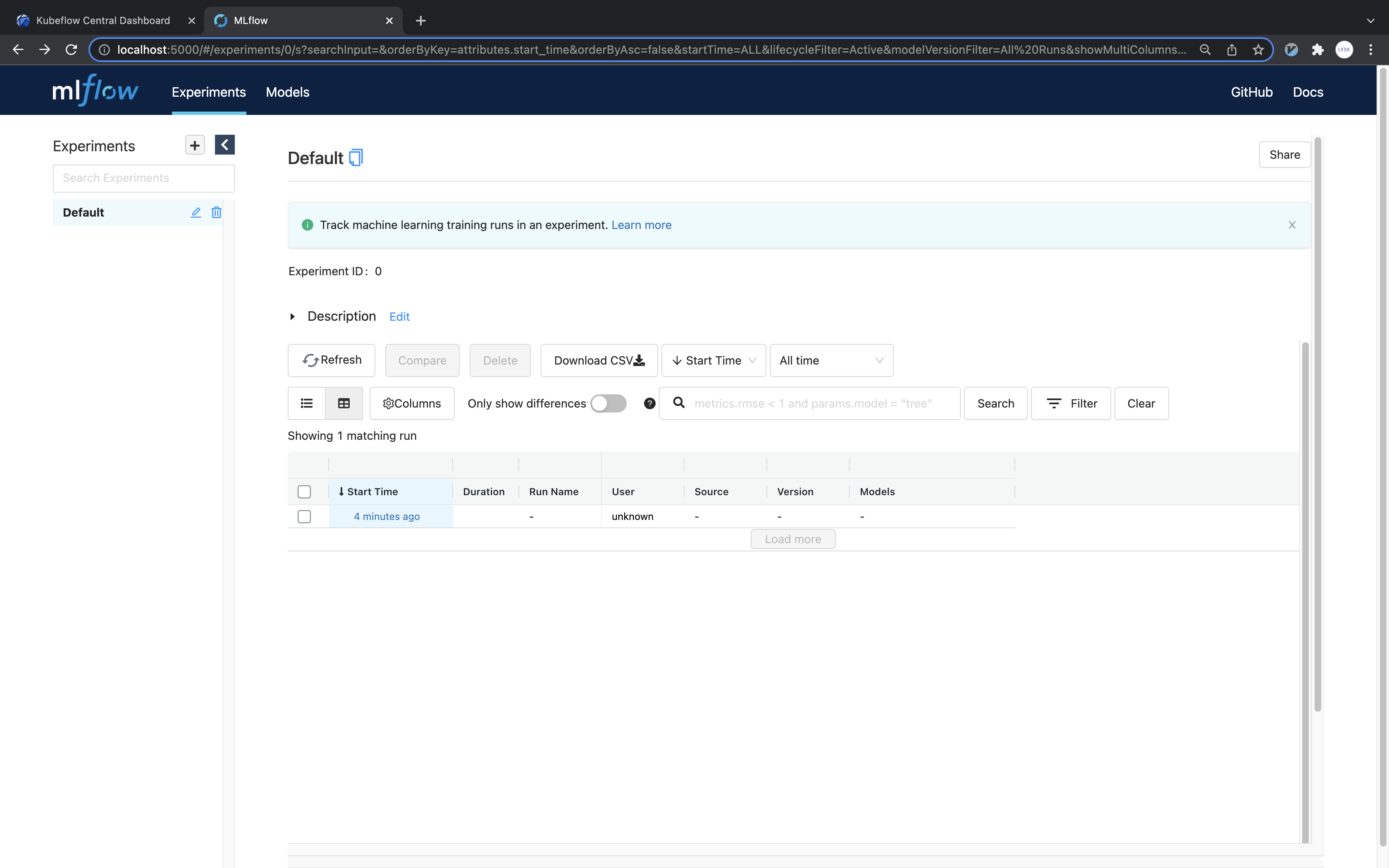
run 을 클릭해서 확인하면 학습한 모델 파일이 있는 것을 확인할 수 있습니다.