2. Kubeflow Concepts
Component
컴포넌트(Component)는 컴포넌트 콘텐츠(Component contents)와 컴포넌트 래퍼(Component wrapper)로 구성되어 있습니다. 하나의 컴포넌트는 컴포넌트 래퍼를 통해 kubeflow에 전달되며 전달된 컴포넌트는 정의된 컴포넌트 콘텐츠를 실행(execute)하고 아티팩트(artifacts)들을 생산합니다.

Component Contents
컴포넌트 콘텐츠를 구성하는 것은 총 3가지가 있습니다.

- Environemnt
- Python code w\ Config
- Generates Artifacts
예시와 함께 각 구성 요소가 어떤 것인지 알아보도록 하겠습니다. 다음과 같이 데이터를 불러와 SVC(Support Vector Classifier)를 학습한 후 SVC 모델을 저장하는 과정을 적은 파이썬 코드가 있습니다.
import dill
import pandas as pd
from sklearn.svm import SVC
train_data = pd.read_csv(train_data_path)
train_target= pd.read_csv(train_target_path)
clf= SVC(
kernel=kernel
)
clf.fit(train_data)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
위의 파이썬 코드는 다음과 같이 컴포넌트 콘텐츠로 나눌 수 있습니다.

Environment는 파이썬 코드에서 사용하는 패키지들을 import하는 부분입니다.
다음으로 Python Code w\ Config 에서는 주어진 Config를 이용해 실제로 학습을 수행합니다.
마지막으로 아티팩트를 저장하는 과정이 있습니다.
Component Wrapper
컴포넌트 래퍼는 컴포넌트 콘텐츠에 필요한 Config를 전달하고 실행시키는 작업을 합니다.
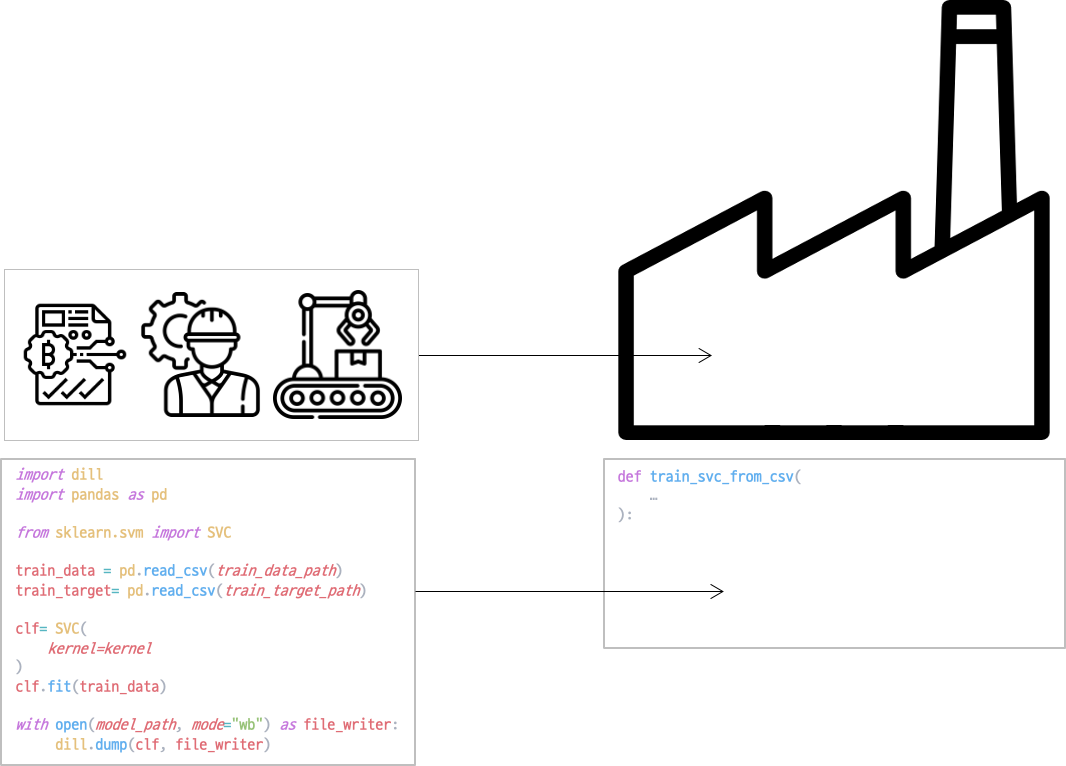
Kubeflow에서는 컴포넌트 래퍼를 위의 train_svc_from_csv와 같이 함수의 형태로 정의합니다.
컴포넌트 래퍼가 콘텐츠를 감싸면 다음과 같이 됩니다.

Artifacts
위의 설명에서 컴포넌트는 아티팩트(Artifacts)를 생성한다고 했습니다. 아티팩트란 evaluation result, log 등 어떤 형태로든 파일로 생성되는 것을 통틀어서 칭하는 용어입니다. 그중 우리가 관심을 두는 유의미한 것들은 다음과 같은 것들이 있습니다.
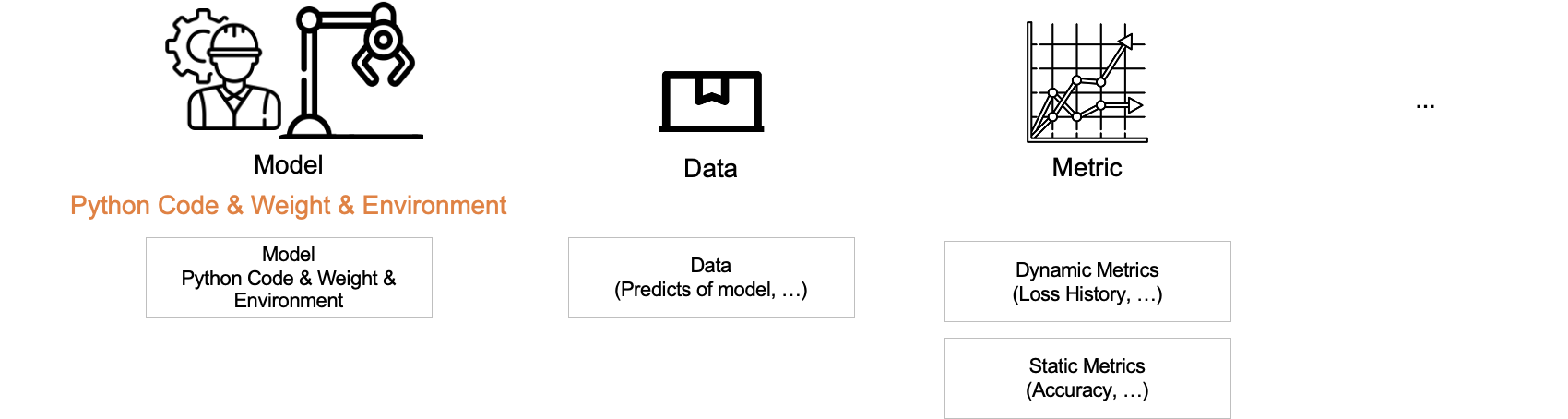
- Model
- Data
- Metric
- etc
Model
저희는 모델을 다음과 같이 정의 했습니다.
모델이란 파이썬 코드와 학습된 Weights와 Network 구조 그리고 이를 실행시키기 위한 환경이 모두 포함된 형태
Data
데이터는 전 처리된 피처, 모델의 예측 값 등을 포함합니다.
Metric
Metric은 동적 지표와 정적 지표 두 가지로 나누었습니다.
- 동적 지표란 train loss와 같이 학습이 진행되는 중 에폭(Epoch)마다 계속해서 변화하는 값을 의미합니다.
- 정적 지표란 학습이 끝난 후 최종적으로 모델을 평가하는 정확도 등을 의미합니다.
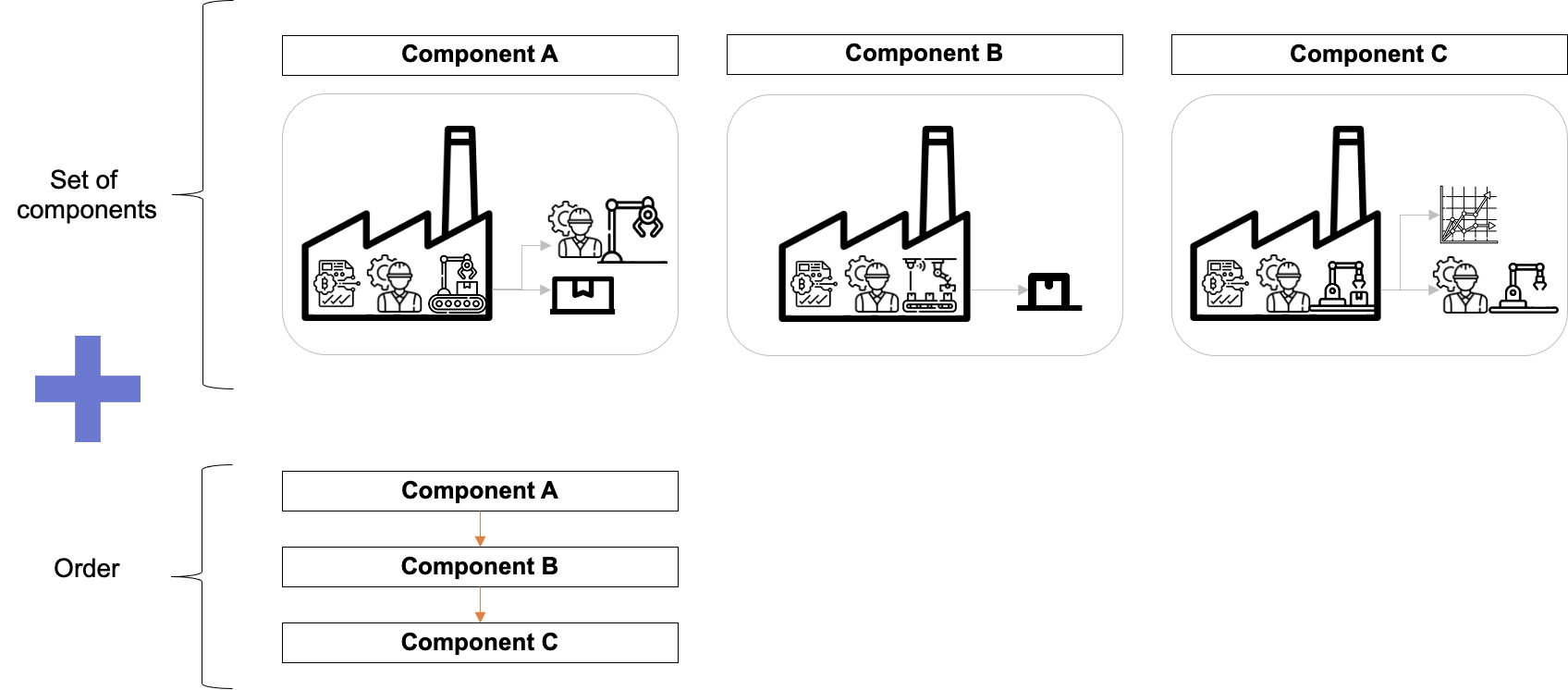
Pipeline
파이프라인은 컴포넌트의 집합과 컴포넌트를 실행시키는 순서도로 구성되어 있습니다. 이 때, 순서도는 방향 순환이 없는 그래프로 이루어져 있으며, 간단한 조건문을 포함할 수 있습니다.
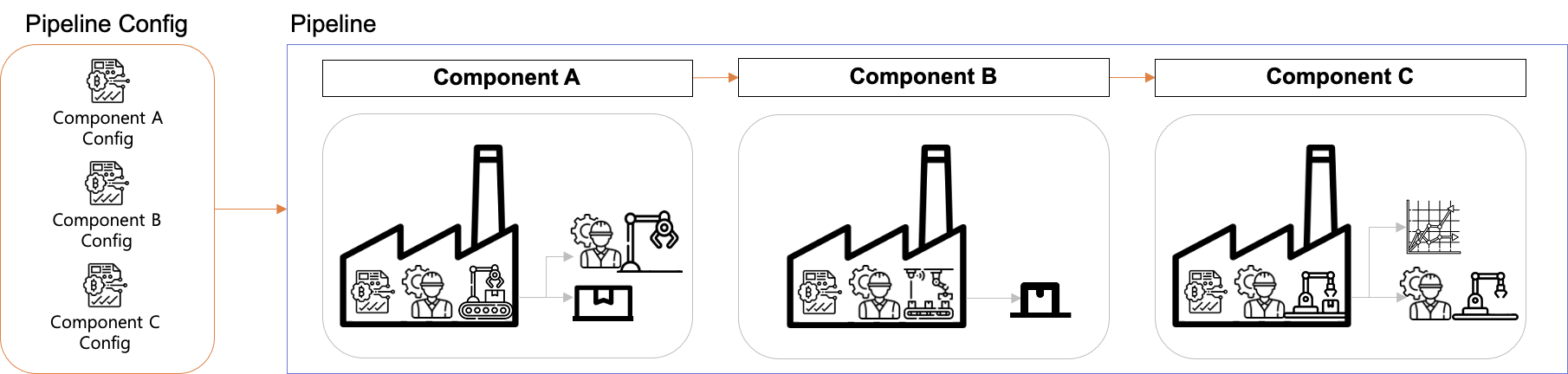
Pipeline Config
앞서 컴포넌트를 실행시키기 위해서는 Config가 필요하다고 설명했습니다. 파이프라인을 구성하는 컴포넌트의 Config 들을 모아 둔 것이 파이프라인 Config입니다.
Run
파이프라인이 필요로 하는 파이프라인 Config가 주어져야지만 파이프라인을 실행할 수 있습니다.
Kubeflow에서는 실행된 파이프라인을 Run 이라고 부릅니다.
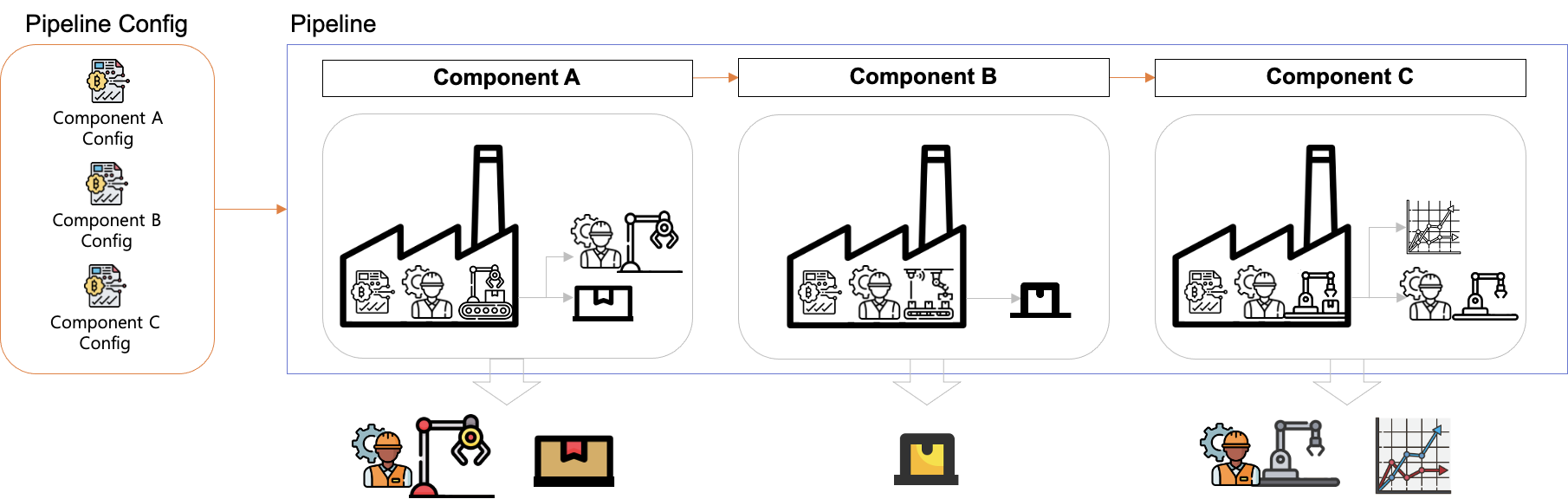
파이프라인이 실행되면 각 컴포넌트가 아티팩트들을 생성합니다. Kubeflow pipeline에서는 Run 하나당 고유한 ID 를 생성하고, Run에서 생성되는 모든 아티팩트들을 저장합니다.
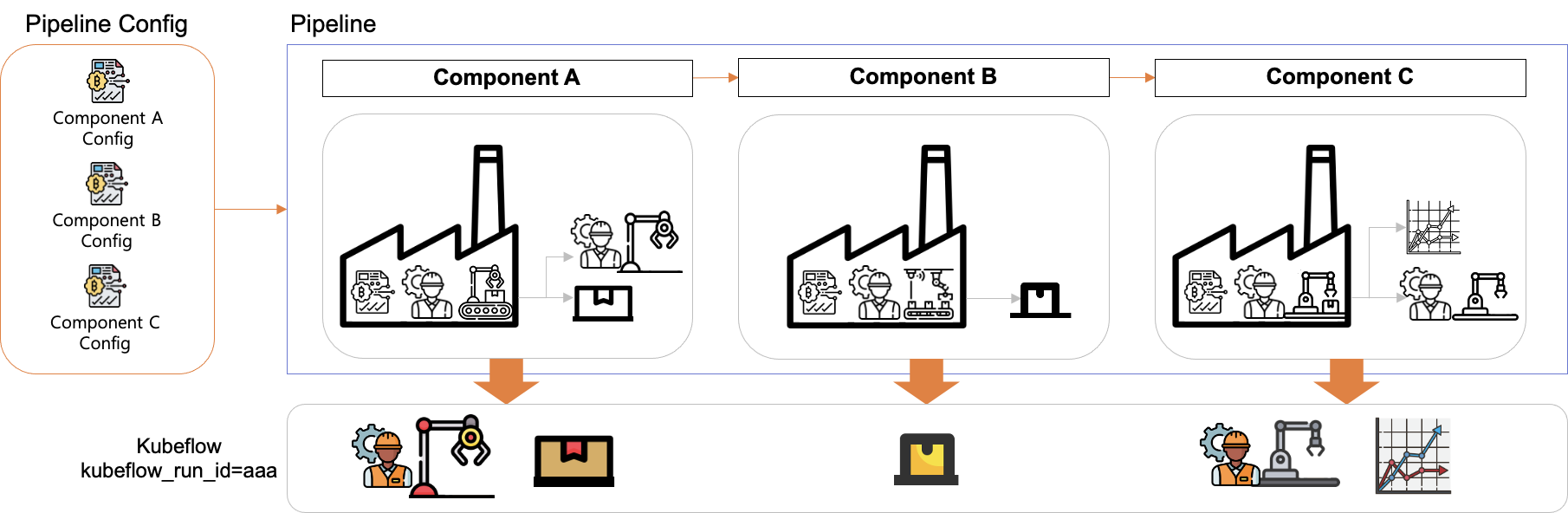
그러면 이제 직접 컴포넌트와 파이프라인을 작성하는 방법에 대해서 알아보도록 하겠습니다.