13. Component - Debugging
Debugging Pipeline
이번 페이지에서는 Kubeflow 컴포넌트를 디버깅하는 방법에 대해서 알아봅니다.
Failed Component
이번 페이지에서는 Component - MLFlow 에서 이용한 파이프라인을 조금 수정해서 사용합니다.
우선 컴포넌트가 실패하도록 파이프라인을 변경하도록 하겠습니다.
from functools import partial
import kfp
from kfp.components import InputPath, OutputPath, create_component_from_func
from kfp.dsl import pipeline
@partial(
create_component_from_func,
packages_to_install=["pandas", "scikit-learn"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data["sepal length (cm)"] = None
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
@partial(
create_component_from_func,
packages_to_install=["pandas"],
)
def drop_na_from_csv(
data_path: InputPath("csv"),
output_path: OutputPath("csv"),
):
import pandas as pd
data = pd.read_csv(data_path)
data = data.dropna()
data.to_csv(output_path, index=False)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
input_example_path: OutputPath("dill"),
signature_path: OutputPath("dill"),
conda_env_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)
@pipeline(name="debugging_pipeline")
def debugging_pipeline(kernel: str):
iris_data = load_iris_data()
drop_data = drop_na_from_csv(data=iris_data.outputs["data"])
model = train_from_csv(
train_data=drop_data.outputs["output"],
train_target=iris_data.outputs["target"],
kernel=kernel,
)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(debugging_pipeline, "debugging_pipeline.yaml")
수정한 점은 다음과 같습니다.
- 데이터를 불러오는
load_iris_data컴포넌트에서sepal length (cm)피처에None값을 주입 drop_na_from_csv컴포넌트에서drop_na()함수를 이용해 na 값이 포함된row를 제거
이제 파이프라인을 업로드하고 실행해 보겠습니다.
실행 후 Run을 눌러서 확인해보면 Train from csv 컴포넌트에서 실패했다고 나옵니다.
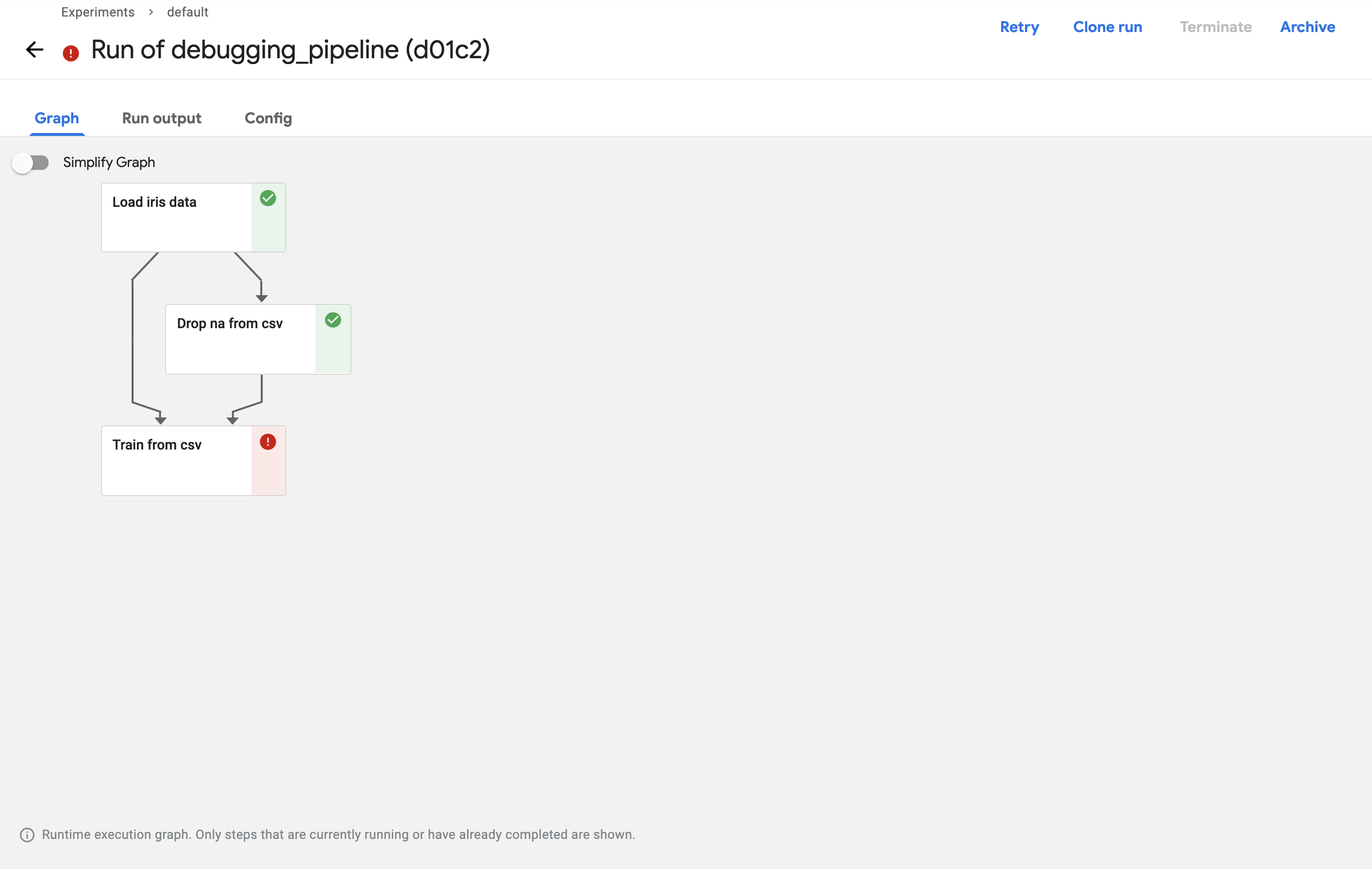
실패한 컴포넌트를 클릭하고 로그를 확인해서 실패한 이유를 확인해 보겠습니다.
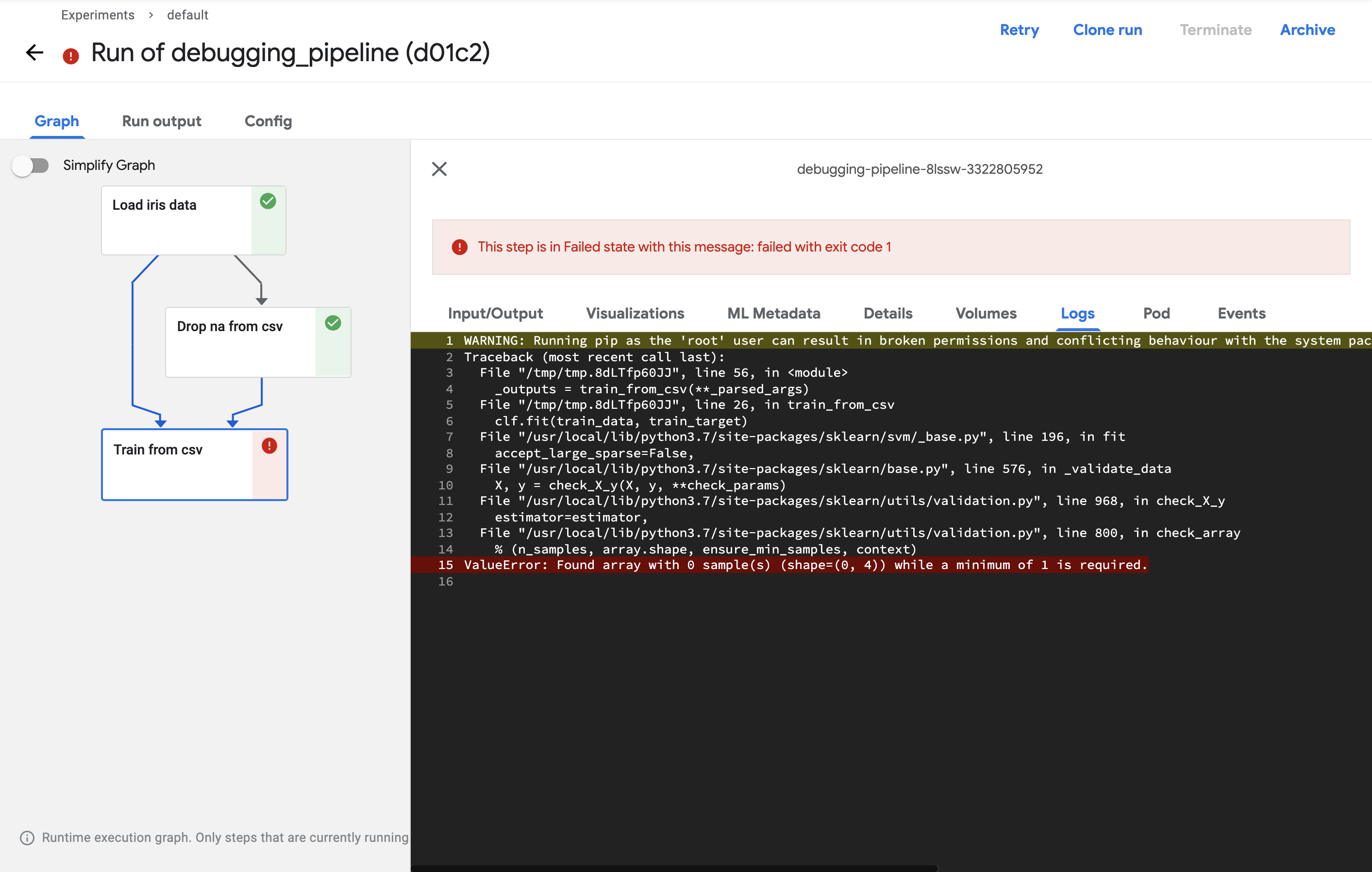
로그를 확인하면 데이터의 개수가 0이여서 실행되지 않았다고 나옵니다.
분명 정상적으로 데이터를 전달했는데 왜 데이터의 개수가 0개일까요?
이제 입력받은 데이터에 어떤 문제가 있었는지 확인해 보겠습니다.
우선 컴포넌트를 클릭하고 Input/Ouput 탭에서 입력값으로 들어간 데이터들을 다운로드 받습니다.
다운로드는 빨간색 네모로 표시된 곳의 링크를 클릭하면 됩니다.
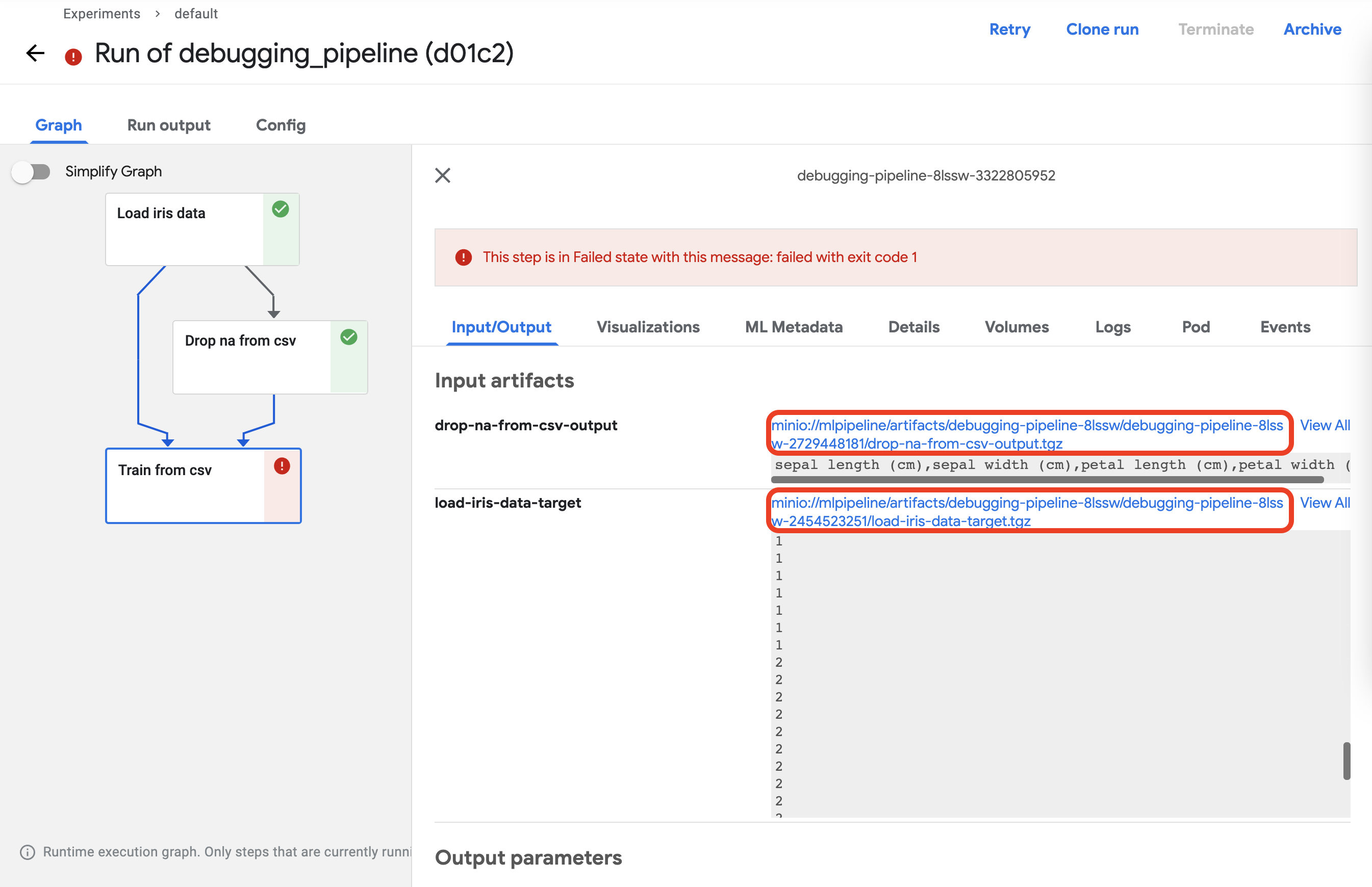
두 개의 파일을 같은 경로에 다운로드합니다.
그리고 해당 경로로 이동해서 파일을 확인합니다.
ls
다음과 같이 두 개의 파일이 있습니다.
drop-na-from-csv-output.tgz load-iris-data-target.tgz
압축을 풀어보겠습니다.
tar -xzvf load-iris-data-target.tgz ; mv data target.csv
tar -xzvf drop-na-from-csv-output.tgz ; mv data data.csv
그리고 이를 주피터 노트북을 이용해 컴포넌트 코드를 실행합니다.
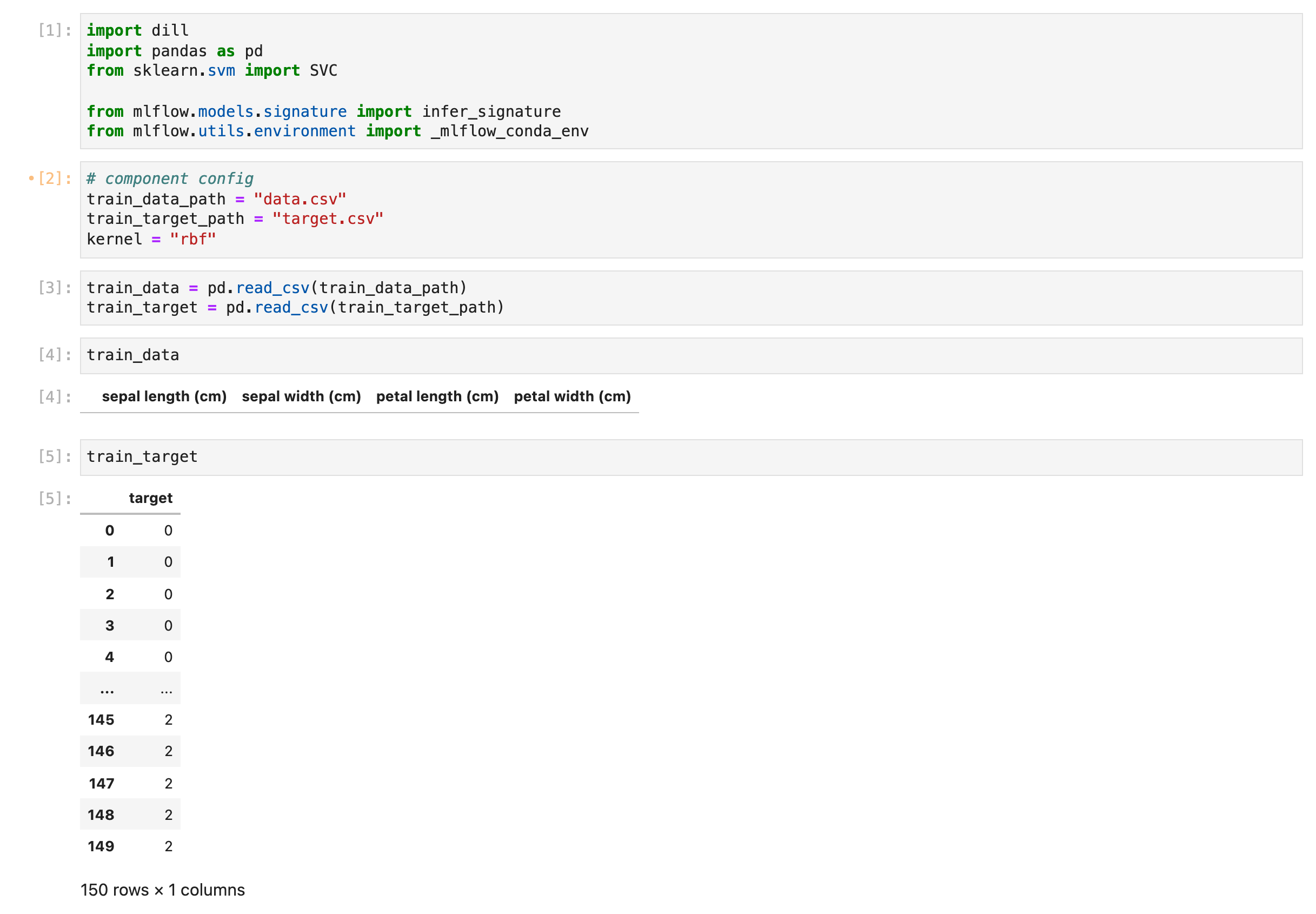
디버깅을 해본 결과 dropna 할 때 column을 기준으로 drop을 해야 하는데 row를 기준으로 drop을 해서 데이터가 모두 사라졌습니다. 이제 문제의 원인을 알아냈으니 column을 기준으로 drop이 되게 컴포넌트를 수정합니다.
@partial(
create_component_from_func,
packages_to_install=["pandas"],
)
def drop_na_from_csv(
data_path: InputPath("csv"),
output_path: OutputPath("csv"),
):
import pandas as pd
data = pd.read_csv(data_path)
data = data.dropna(axis="columns")
data.to_csv(output_path, index=False)
수정 후 파이프라인을 다시 업로드하고 실행하면 다음과 같이 정상적으로 수행하는 것을 확인할 수 있습니다.